[Paper reading] Swin Transformer
2023. 9. 4. 07:31ㆍArtificialIntelligence/PaperReading
Swin Transformer
Hierarchical Vision Transformer using Shifted Windows

Abstract
- This paper presents a new vision Transformer, called Swin Transformer, that capably serves as a general-purpose backbone for computer vision.
- Challenges in adapting Transformer from language to vision arise from differences between the two domains, such as large variations in the scale of visual entities and the high resolution of pixels in images compared to words in text.
- To address these differences, we propose a hierarchical Transformer whose representation is computed with Shifted windows. The shifted windowing scheme brings greater efficiency by limiting self-attention computation to non-overlapping local windows while also allowing for cross-window connection. This hierarchical architecture has the flexibility to model at various scales and has linear computational complexity with respect to image size.
- These qualities of Swin Transformer make it compatible with a broad range of vision tasks, including image classification (87.3 top-1 accuracy on ImageNet-1K) and dense prediction tasks such as object detection (58.7 box AP and 51.1 mask AP on COCO test- dev) and semantic segmentation (53.5 mIoU on ADE20K val). Its performance surpasses the previous state-of-the-art by a large margin of +2.7 box AP and +2.6 mask AP on COCO, and +3.2 mIoU on ADE20K, demonstrating the potential of Transformer-based models as vision backbones.
- The hierarchical design and the shifted window approach also prove beneficial for all-MLP architectures. The code and models are publicly available at https://github.com/microsoft/Swin-Transformer.
Introduction
- On the other hand, the evolution of network architectures in natural language processing (NLP) has taken a different path, where the prevalent architecture today is instead the Transformer. Designed for sequence modeling and transduction tasks, the Transformer is notable for its use of attention to model long-range dependencies in the data. Its tremendous success in the language domain has led researchers to investigate its adaptation to computer vision, where it has recently demonstrated promising results on certain tasks, specifically image classification and joint vision-language modeling.
- In this paper, we seek to expand the applicability of Transformer such that it can serve as a general-purpose backbone for computer vision, as it does for NLP and as CNNs do in vision. We observe that significant challenges in transferring its high performance in the language domain to the visual domain can be explained by differences between the two modalities.
- One of these differences involves scale. Unlike the word tokens that serve as the basic elements of processing in language Transformers, visual elements can vary substantially in scale, a problem that receives attention in tasks such as object detection. In existing Transformer-based models , tokens are all of a fixed scale, a property unsuitable for these vision applications.
- Another difference is the much higher resolution of pixels in images compared to words in passages of text. There exist many vision tasks such as semantic segmentation that require dense prediction at the pixel level, and this would be intractable for Transformer on high-resolution images, as the computational complexity of its self-attention is quadratic to image size.
- To overcome these issues, we propose a general-purpose Transformer backbone, called Swin Transformer, which constructs hierarchical feature maps and has linear computational complexity to image size.
- As illustrated in Figure 1, Swin Transformer constructs a hierarchical representation by starting from small-sized patches (outlined in gray) and gradually merging neighboring patches in deeper Transformer layers. With these hierarchical feature maps, the Swin Transformer model can conveniently leverage advanced techniques for dense prediction such as feature pyramid networks (FPN)or U-Net.
- The linear computational complexity is achieved by computing self-attention locally within non-overlapping windows that partition an image (outlined in red). The number of patches in each window is fixed, and thus the complexity becomes linear to image size.
- These merits make Swin Transformer suitable as a general-purpose backbone for various vision tasks, in contrast to previous Transformer based architectures which produce feature maps of a single resolution and have quadratic complexity.
Conclusion
- This paper presents Swin Transformer, a new vision Transformer which produces a hierarchical feature representation and has linear computational complexity with respect to input image size.
- Swin Transformer achieves the state-of-the-art performance on COCO object detection and ADE20K semantic segmentation, significantly surpassing previous best methods. We hope that Swin Transformer’s strong performance on various vision problems will encourage unified modeling of vision and language signals.
- As a key element of Swin Transformer, the shifted window based self-attention is shown to be effective and efficient on vision problems, and we look forward to investigating its use in natural language processing as well.
Conclusion
장점
- 기존 Vision 분야에서 CNN 기반의 backbone을 사용하다가, 이를 NLP 분야에서 활용되던 Transformer (self-attention) 기반으로 넘어가는 과정에 있어서, 주요한 문제점이 무엇인지 파악하고 이를 해결해야나가는 과정이 introduction에서 논리적으로 전개되었다.
- On the other hand, the evolution of network architectures in natural language processing (NLP) has taken a different path, where the prevalent architecture today is instead the Transformer. Designed for sequence modeling and transduction tasks, the Transformer is notable for its use of attention to model long-range dependencies in the data. Its tremendous success in the language domain has led researchers to investigate its adaptation to computer vision, where it has recently demonstrated promising results on certain tasks, specifically image classification and joint vision-language modeling.
- In this paper, we seek to expand the applicability of Transformer such that it can serve as a general-purpose backbone for computer vision, as it does for NLP and as CNNs do in vision. We observe that significant challenges in transferring its high performance in the language domain to the visual domain can be explained by differences between the two modalities.
- These merits make Swin Transformer suitable as a general-purpose backbone for various vision tasks, in contrast to previous Transformer based architectures which produce feature maps of a single resolution and have quadratic complexity.
- general-purpose를 간단히 언급하고 넘어가는 것이 아니라, 다양한 dataset 실험을 통해 image classification, object detection, segmentation 각각에 대한 성능 비교를 도표로 분석하여 제시한 점도 인상깊었다.
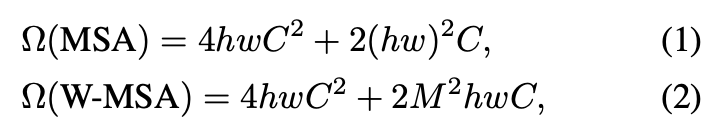
- method 부분에서 계산 복잡도 빅-오메가를 수식으로 정리하여 제시한 점이 직접적으로 global 방식과 local (window based)의 차이를 확인할 수 있어서 좋았다.

- l 번째 블럭에 대하여 MSA(Multi-head self attention)과 MLP block을 통과하였을 때의 output feature 수식을 다음과 같이 제시한 점이 인상깊었다. 처음에는 self attention과 shifted window가 적용되는 과정이 모호하게 다가와서 잘 이해되지 않았는데, 다양한 수식을 함께 제시하여, 단계별 과정에 대해 이해하기 수월하였다.
단점
- Relative position bias
- In computing self-attention, we follow by including a relative position bias B ∈ RM2×M2 to each head in computing similarity:
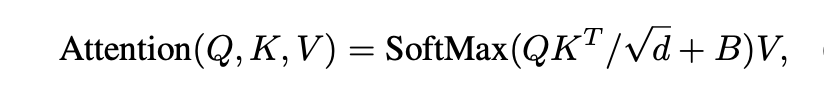
- d is the query/key dimension, and M2 is the number of patches in a window. Since the relative position along each axis lies in the range [−M + 1, M − 1], we parameter- ize a smaller-sized bias matrix Bˆ ∈ R(2M−1)×(2M−1), and values in B are taken from Bˆ.
- We observe significant improvements over counterparts without this bias term or that use absolute position embedding, as shown in Table 4. Further adding absolute position embedding to the input as in drops performance slightly, thus it is not adopted in our implementation.
- The learnt relative position bias in pre-training can be also used to initialize a model for fine-tuning with a different window size through bi-cubic interpolation.
- relative position bias이 무엇이고 왜 사용된 것인지에 대해서 잘 이해되지 않는다. 기존 ViT 논문에서 언급된 inductive bias와 어떤 측면에서 다른 것인지 잘 모르겠다.
- Compared with the state-of-the-art ConvNets, i.e. RegNet and EfficientNet, the Swin Transformer achieves a slightly better speed-accuracy trade-off. Nothing that while RegNet and EfficientNet are obtained via a thorough architecture search, the proposed Swin Transformer is adapted from the standard Transformer and has strong potential for further improvement.
- image classification (Image-1K training) 결과 분석 part에서 Swin Transformer가 CNN 기반의 EfficientNet 보다 더 많은 연상량과 parmas 수를 가짐에도 큰 성능 향상이 없는 것 같다. 해당 실험에서 CNN 대비 Swin Transformer의 장점이 무엇인지 잘 모르겠다.
개선할 점 & Question
- Patch가 merging 되는 과정이 수식만으로는 잘 이해되지 않았다.
- https://heeya-stupidbutstudying.tistory.com/entry/DL-Swin-Transformer-논문-리뷰-Hierarchical-Vision-Transformer-using-Shifted-Windows
[논문리뷰] Swin Transformer - Hierarchical Vision Transformer using Shifted Windows
ViT 논문 리뷰 포스트에 이어 트랜스포머를 이용해 image recognition task를 수행하는 딥러닝 모델들에 대해 계속 다뤄보려한다. 이번 주제는 Swin Transformer로, 2021년 3월 마이크로소프트(Microsoft Research A
heeya-stupidbutstudying.tistory.com
'ArtificialIntelligence > PaperReading' 카테고리의 다른 글
| [Paper reading] Dataset Condensation reading (0) | 2023.09.11 |
|---|---|
| [Paper reading] Dataset Condensation Summary (0) | 2023.09.10 |
| [Paper reading] Transformers for image recognition, ViT (0) | 2023.08.28 |
| [Paper reading] Attention is all you need, Transformer (0) | 2023.08.25 |
| [Paper reading] DenseNet (0) | 2023.08.22 |