2023. 10. 29. 18:52ㆍArtificialIntelligence/2023GoogleMLBootcamp
Learning Word Embeddings

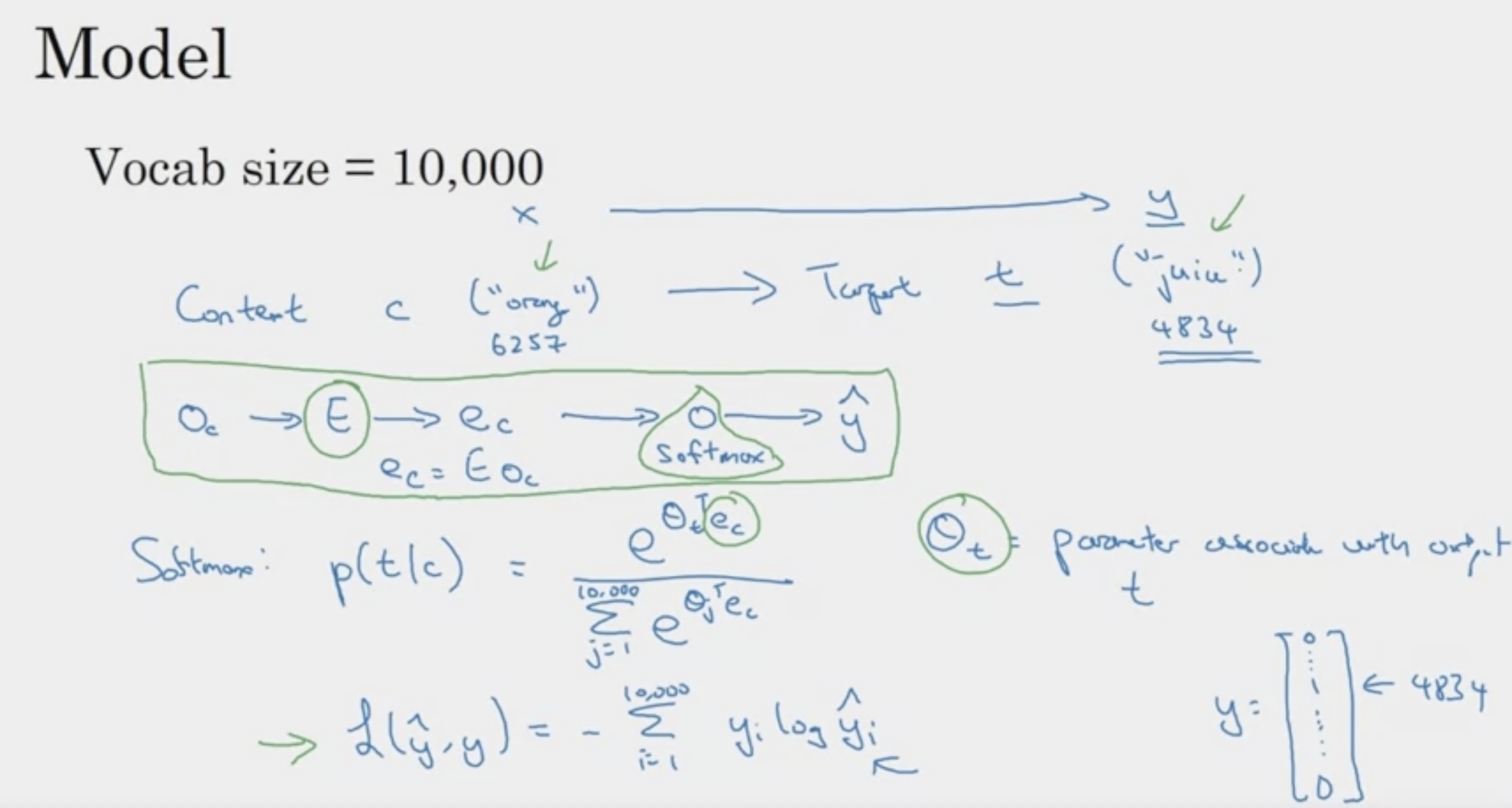
blank를 채우는 방식 (예측하는)
만약, 빈칸 앞의 4 단어만 보고 예측한다면? (앞에 i want는 삭제, 1800 -> 1200)

context에 맞추어 (기준에 따라)
타겟을 예측하는데 활용할 단어가 달라진다.
Word2Vec

랜덤하게 target 벡터를 고른다. (특정 범위의 윈도우 사이즈 내부에서)
계산 비용 -> slow 문제

가속화를 위해 트리 구조를 활용 (저빈도 -> 더 deep)
Hierarchical softmax

휴리스틱한 다양한 방법들이 적용될 수 있다.
Negative Sampling

인풋으로 두 단어 -> target을 예측하는 문제 (0 or 1)
비교적 큰 데이터 셋 -> K를 작게 잡는다.

첫번째 주스만 1 -> positive
이후로 K개는 모두 0 -> negative
따라서 negative sampling 이라고 불리는 것
기존의 무거운 시그마 수식보다 훨씬 계산 복잡도가 개선 !
softmax => binary classification problem으로 바꾸어 해결

어떻게 0 샘플들을 고르냐? frequency에 따라 계산
GloVe Word Vectors



Sentiment Classification

labeling이 된 데이터가 부족하다는 문제점이 있다.
common 대중의 반응이 궁금할 때


RNN 구조 중 many to one과 연관 O
여러 단어 (문장) input -> output (감정, timeseries 값 X)
Debiasing Word Embeddings

ML -> 중요한 판단의 도구가 됨 -> 이러한 바람직하지 않은 bias를 제거하는 것은 중요하다
인간의 머리보다, AI의 편견을 제거하는 것이 더 쉽다.

gender 벡터 방향을 찾고, neutralize (축에 투영)
이후 거리가 같도록 equalize (ex, 베이비시터 포인트로부터 할머니, 할아버지 포인트의 거리가 같도록 조정)
PCA 같고 신기하다
'ArtificialIntelligence > 2023GoogleMLBootcamp' 카테고리의 다른 글
| [GoogleML] Transformer Network (Final) (0) | 2023.10.30 |
|---|---|
| [GoogleML] Sequence Models & Attention Mechanism (1) | 2023.10.30 |
| [GoogleML] Natural Language Processing & Word Embeddings (1) | 2023.10.29 |
| [GoogleML] Recurrent Neural Networks (1) | 2023.10.17 |
| [GoogleML] Convolutional Neural Networks 수료 (0) | 2023.10.11 |