[Paper review] Xen and the Art of Virtualization
2024. 3. 15. 18:35ㆍComputerScience/OperatingSystem
Xen and the Art of Virtualization

Abstraction
- Numerous systems have been designed which use virtualization to subdivide the ample resources of a modern computer. Some require specialized hardware, or cannot support commodity operating systems. Some target 100% binary compatibility at the expense of performance. Others sacrifice security or functionality for speed. Few offer resource isolation or performance guarantees; most provide only best-effort provisioning, risking denial of service.
- Xen, an x86 virtual machine monitor which allows multiple commodity operating systems to share conventional hardware in a safe and resource managed fashion, but without sacrificing either performance or functionality.
- This is achieved by providing an idealized virtual machine abstraction to which operating systems such as Linux, BSD and Windows XP, can be ported with minimal effort. (GuestOS들에게)
- Our design is targeted at hosting up to 100 virtual machine instances simultaneously on a modern server. The virtualization approach taken by Xen is extremely efficient: we allow operating systems such as Linux and Windows XP to be hosted simultaneously for a negligible performance overhead — at most a few percent compared with the unvirtualized case.

Introduction
- Successful partitioning of a machine to support the concurrent execution of multiple operating systems poses several challenges.
// 하나의 machine을 concurrent 한 여러 OS로 실행할 때 주의해야 할 3가지 - Firstly, virtual machines must be isolated from one another: it is not acceptable for the execution of one to adversely affect the performance of another. This is particularly true when virtual machines are owned by mutually untrusting users.
- Secondly, it is necessary to support a variety of different operating systems to accommodate the heterogeneity of popular applications.
- Thirdly, the performance overhead introduced by virtualization should be small.
- There are a number of ways to build a system to host multiple applications and servers on a shared machine. Perhaps the simplest is to deploy one or more hosts running a standard operating system such as Linux or Windows, and then to allow users to install files and start processes — protection between applications being provided by conventional OS techniques. Experience shows that system administration can quickly become a time-consuming task due to complex configuration interactions between supposedly disjoint applications.
- More importantly, such systems do not adequately support performance isolation; the scheduling priority, memory demand, network traffic and disk accesses of one process impact the performance of others. This may be acceptable when there is adequate provisioning and a closed user group (such as in the case of computational grids, or the experimental PlanetLab platform [33]), but not when resources are oversubscribed, or users uncooperative.
- One way to address this problem is to retrofit support for performance isolation to the operating system. This has been demonstrated to a greater or lesser degree with resource containers [3], Linux/RK [32], QLinux [40] and SILK [4].
- One difficulty with such approaches is ensuring that all resource usage is accounted to the correct process — consider, for example, the complex interactions between applications due to buffer cache or page replacement algorithms. This is effectively the problem of “QoS crosstalk” [41] within the operating system.
- Performing multiplexing at a low level can mitigate this problem, as demonstrated by the Exokernel [23] and Nemesis [27] operating systems. Unintentional or undesired interactions between tasks are minimized.
- We use this same basic approach to build Xen, which multiplexes physical resources at the granularity of an entire operating system and is able to provide performance isolation between them. In contrast to process-level multiplexing this also allows a range of guest operating systems to gracefully coexist rather than mandating a specific application binary interface.
- There is a price to pay for this flexibility — running a full OS is more heavyweight than running a process, both in terms of initialization (e.g. booting or resuming versus fork and exec), and in terms of resource consumption.
// Full OS의 단점 - heavy weight and time-consuming
Design principles for Xen
- Support for unmodified application binaries is essential, or users will not transition to Xen.
Hence we must virtualize all architectural features required by existing standard ABIs.
// ABI - Application Binary Interface 바이너리 level의 인터페이스 - Supporting full multi-application operating systems is important, as this allows complex server configurations to be virtualized within a single guest OS instance.
- Paravirtualization is necessary to obtain high performance and strong resource isolation on uncooperative machine architectures such as x86.
- Even on cooperative machine architectures, completely hiding the effects of resource virtualization from guest OSes risks both correctness and performance.
Memory Management
- Virtualizing memory is undoubtedly the most difficult part of paravirtualizing an architecture, both in terms of the mechanisms required in the hypervisor and modifications required to port each guest OS. The task is easier if the architecture provides a software managed TLB as these can be efficiently virtualized in a simple manner [13]. A tagged TLB is another useful feature supported by most server-class RISC architectures, including Alpha, MIPS and SPARC. Associating an address-space identifier tag with each TLB entry allows the hypervisor and each guest OS to efficiently coexist in separate address spaces because there is no need to flush the entire TLB when transferring execution.
- Unfortunately, x86 does not have a software-managed TLB; instead TLB misses are serviced automatically by the processor by walking the page table structure in hardware. Thus to achieve the best possible performance, all valid page translations for the current address space should be present in the hardware-accessible page table.
- Moreover, because the TLB is not tagged, address space switches typically require a complete TLB flush. Given these limitations, we made two decisions
(i) guest OSes are responsible for allocating and managing the hardware page tables, with minimal involvement from Xen to ensure safety and isolation
(ii) Xen exists in a 64MB section at the top of every address space, thus avoiding a TLB flush when entering and leaving the hypervisor.
- Each time a guest OS requires a new page table, it allocates and initializes a page from its own memory reservation and registers it with Xen. At this point the OS must relinquish (양도하다) direct write privileges to the page-table memory: all subsequent updates must be validated by Xen. This restricts updates in a number of ways, including only allowing an OS to map pages that it owns, and disallowing writable mappings of page tables. Guest OSes may batch update requests to amortize the overhead of entering the hypervisor.
- The top 64MB region of each address space, which is reserved for Xen, is not accessible or remappable by guest OSes. This address region is not used by any of the common x86 ABIs however, so this restriction does not break application compatibility.
- Segmentation is virtualized in a similar way, by validating updates to hardware segment descriptor tables. The only restrictions on x86 segment descriptors are:
(i) they must have lower privilege than Xen
(ii) they may not allow any access to the Xen-reserved portion of the address space.
CPU Virtualization
- Virtualizing the CPU has several implications for guest OSes. Principally, the insertion of a hypervisor below the operating system violates the usual assumption that the OS is the most privileged entity in the system.
- In order to protect the hypervisor from OS misbehavior (and domains from one another) guest OSes must be modified to run at a lower privilege level.
- Many processor architectures only provide two privilege levels. In these cases the guest OS would share the lower privilege level with applications. The guest OS would then protect itself by running in a separate address space from its applications, and indirectly pass control to and from applications via the hypervisor to set the virtual privilege level and change the current address space. Again, if the processor’s TLB supports address-space tags then expensive TLB flushes can be avoided.
- Efficient virtualizion of privilege levels is possible on x86 because it supports four distinct privilege levels in hardware. The x86 privilege levels are generally described as rings, and are numbered from zero (most privileged) to three (least privileged).
- OS code typically executes in ring 0 because no other ring can execute privileged instructions,
while ring 3 is generally used for application code. - To our knowledge, rings 1 and 2 have not been used by any well-known x86 OS since OS/2.
Any OS which follows this common arrangement can be ported to Xen by modifying it to execute in ring 1. This prevents the guest OS from directly executing privileged instructions, yet it remains safely isolated from applications running in ring 3. - Privileged instructions are paravirtualized by requiring them to be validated and executed within Xen— this applies to operations such as installing a new page table, or yielding the processor when idle (rather than attempting to hlt it). Any guest OS attempt to directly execute a privileged instruction is failed by the processor, either silently or by taking a fault, since only Xen executes at a sufficiently privileged level.
- Exceptions, including memory faults and software traps, are virtualized on x86 very straightforwardly. When an exception occurs while executing outside ring 0, Xen’s handler creates a copy of the exception stack frame on the guest OS stack and returns control to the appropriate registered handler.
- Typically only two types of exception occur frequently enough to affect system performance: system calls (which are usually implemented via a software exception), and page faults.
We improve the performance of system calls by allowing each guest OS to register a ‘fast’ exception handler which is accessed directly by the processor without indirecting via ring 0; this handler is validated before installing it in the hardware exception table. - Unfortunately it is not possible to apply the same technique to the page fault handler because only code executing in ring 0 can read the faulting address from register CR2; page faults must therefore always be delivered via Xen so that this register value can be saved for access in ring 1.
- Safety is ensured by validating exception handlers when they are presented to Xen. The only required check is that the handler’s code segment does not specify execution in ring 0. Since no guest OS can create such a segment, it suffices to compare the specified segment selector to a small number of static values which are reserved by Xen.
- Apart from this, any other handler problems are fixed up during exception propagation — for example, if the handler’s code segment is not present or if the handler is not paged into memory then an appropriate fault will be taken when Xen executes the iret instruction which returns to the handler. Xen detects these “double faults” by checking the faulting program counter value: if the address resides within the exception-virtualizing code then the offending guest OS is terminated.
- Note that this “lazy” checking is safe even for the direct system-call handler: access faults will occur when the CPU attempts to directly jump to the guest OS handler. In this case the faulting address will be outside Xen (since Xen will never execute a guest OS system call) and so the fault is virtualized in the normal way. If propagation of the fault causes a further “double fault” then the guest OS is terminated as described above.
Device I/O
- Rather than emulating existing hardware devices, as is typically done in fully-virtualized environments, Xen exposes a set of clean and simple device abstractions. This allows us to design an interface that is both efficient and satisfies our requirements for protection and isolation. To this end, I/O data is transferred to and from each domain (== Guest OS를 의미함) via Xen, using shared-memory, asynchronous buffer-descriptor rings.
- These provide a high-performance communication mechanism for passing buffer information vertically through the system, while allowing Xen to efficiently perform validation checks (for example, checking that buffers are contained within a domain’s memory reservation).
- Similar to hardware interrupts, Xen supports a lightweight event-delivery mechanism which is used for sending asynchronous notifications to a domain. These notifications are made by updating a bitmap of pending event types and, optionally, by calling an event handler specified by the guest OS. These callbacks can be ‘held off’ at the discretion of the guest OS — to avoid extra costs incurred by frequent wake-up notifications, for example.
Physical Memory
- The initial memory allocation, or reservation, for each domain is specified at the time of its creation; memory is thus statically partitioned between domains, providing strong isolation. A maximum-allowable reservation may also be specified: if memory pressure within a domain increases, it may then attempt to claim additional memory pages from Xen, up to this reservation limit.
- Conversely, if a domain wishes to save resources, perhaps to avoid incurring unnecessary costs, it can reduce its memory reservation by releasing memory pages back to Xen. (역으로 조절도 가능!)
- XenoLinux implements a balloon driver [42], which adjusts a domain’s memory usage by passing memory pages back and forth between Xen and XenoLinux’s page allocator. Although we could modify Linux’s memory-management routines directly, the balloon driver makes adjustments by using existing OS functions, thus simplifying the Linux porting effort.
- However, paravirtualization can be used to extend the capabilities of the balloon driver; for example, the out-of-memory handling mechanism in the guest OS can be modified to automatically alleviate memory pressure by requesting more memory from Xen.
- Most operating systems assume that memory comprises at most a few large contiguous extents. Because Xen does not guarantee to allocate contiguous regions of memory, guest OSes will typically create for themselves the illusion of contiguous physical memory, even though their underlying allocation of hardware memory is sparse.
- Mapping from physical to hardware addresses is entirely the responsibility of the guest OS, which can simply maintain an array indexed by physical page frame number. Xen supports efficient hardware-to-physical mapping by providing a shared translation array that is directly readable by all domains – updates to this array are validated by Xen to ensure that the OS concerned owns the relevant hardware page frames.
- Note that even if a guest OS chooses to ignore hardware addresses in most cases, it must use the translation tables when accessing its page tables (which necessarily use hardware addresses). Hardware addresses may also be exposed to limited parts of the OS’s memory-management system to optimize memory access. For example, a guest OS might allocate particular hardware pages so as to optimize placement within a physically indexed cache [24], or map naturally aligned contiguous portions of hardware memory using superpages [30].
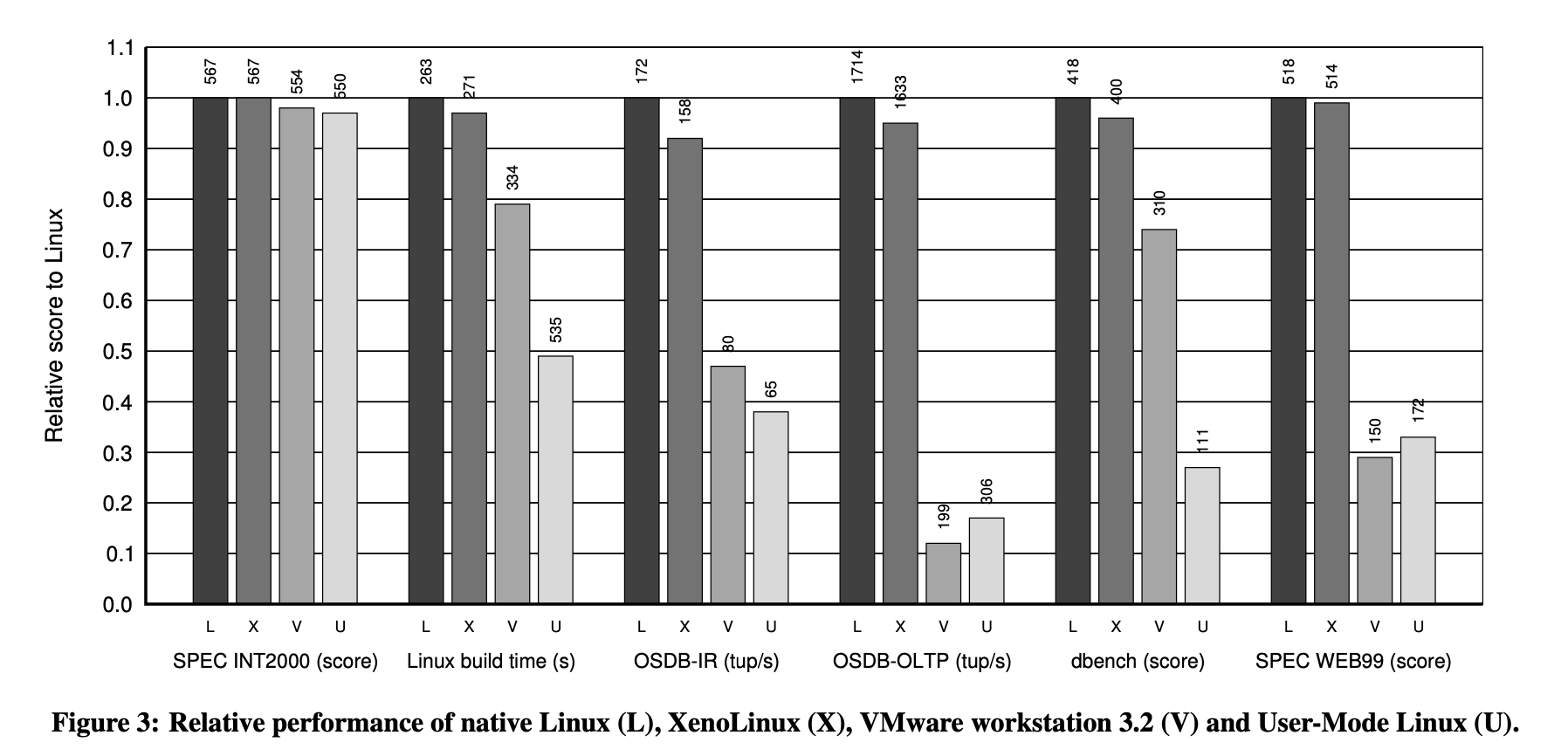
Conclusion
- We have presented the Xen hypervisor which partitions the resources of a computer between domains running guest operating systems. Our paravirtualizing design places a particular emphasis on performance and resource management. We have also described and evaluated XenoLinux, a fully-featured port of a Linux 2.4 kernel that runs over Xen.
- Xen provides an excellent platform for deploying a wide variety of network-centric services, such as local mirroring of dynamic web content, media stream transcoding and distribution, multiplayer game and virtual reality servers, and ‘smart proxies’ [2] to provide a less ephemeral network presence for transiently-connected devices.
- Xen directly addresses the single largest barrier to the deployment of such services: the present inability to host transient servers for short periods of time and with low instantiation costs. By allowing 100 operating systems to run on a single server, we reduce the associated costs by two orders of magnitude. Furthermore, by turning the setup and configuration of each OS into a software concern, we facilitate much smaller-granularity timescales of hosting.
- As our experimental results show in Section 4, the performance of XenoLinux over Xen is practically equivalent to the performance of the baseline Linux system. This fact, which comes from the careful design of the interface between the two components, means that there is no appreciable cost in having the resource management facilities available.
- Our ongoing work to port the BSD and Windows XP kernels to operate over Xen is confirming the generality of the interface that Xen exposes.
참고문헌
Barham, Paul et al. “Xen and the art of virtualization.” Symposium on Operating Systems Principles (2003).
'ComputerScience > OperatingSystem' 카테고리의 다른 글
| [OS Project] Chap4. Booting the Kernel (0) | 2025.01.13 |
|---|---|
| [OS Project] 운영체제 구현하기 프로젝트 (0) | 2025.01.10 |
| 1. Virtualization (0) | 2023.09.08 |
| [운영체제] 기말고사 Summary (0) | 2023.07.21 |
| [운영체제] Security & Cryptography (0) | 2023.06.12 |