2024. 11. 13. 23:29ㆍArtificialIntelligence/ECCV2024
ECCV 2024. 10. 01. Tuesday
Oral 2B: Recognition
1) Generative Models

Gold Room에서 생성모델 오럴 세션이 있었다.
엄청엄청엄청 넓은 홀이었다 😲






발표 듣다가 티모시 샬라메가 등장해서 너무 반가웠다.
그런데 연예인 사진들을 저렇게 막 사용해도 괜찮은건가..? 이런 생각도 들었다.
AI 모델에 돌릴 때, 초상권은 별개의 문제인건가 .?? 무튼 ..

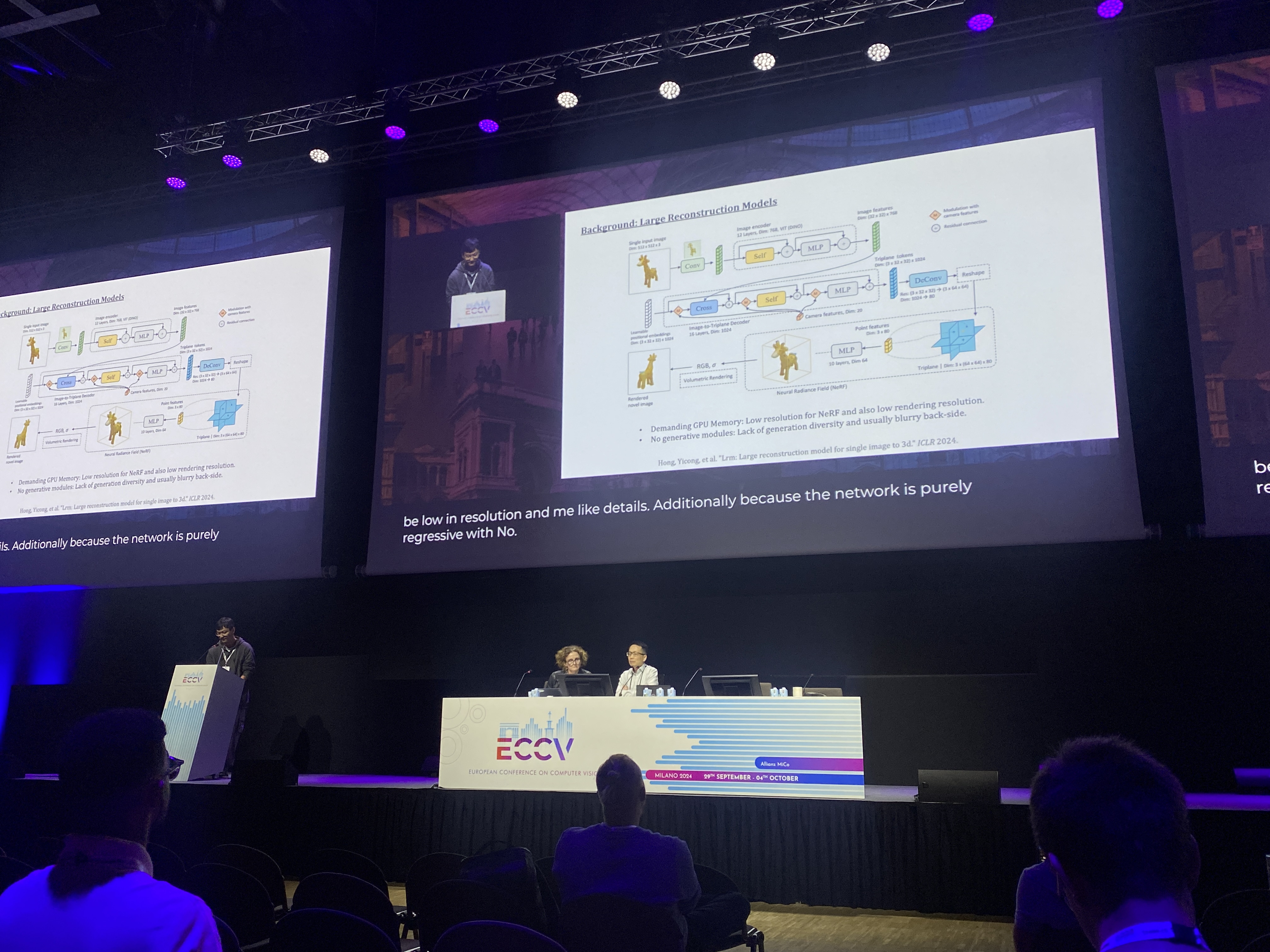

아무래도 시각적으로 보여지는게 많아서, 재미있게 들었지만,
기술 자체에 의미가 있다고 느끼지는 못했다.
2) Recognition


# Google Mobile-Net


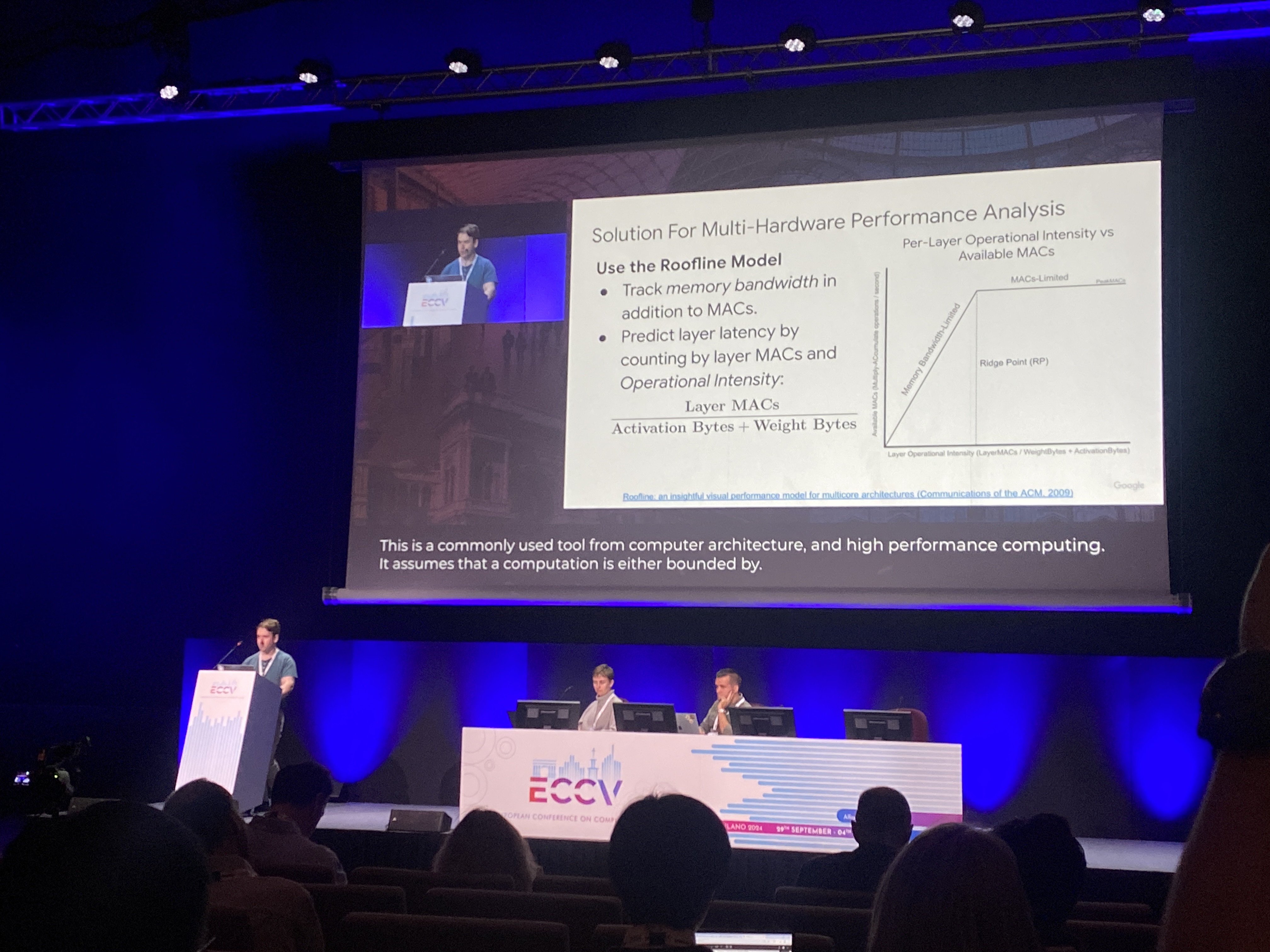
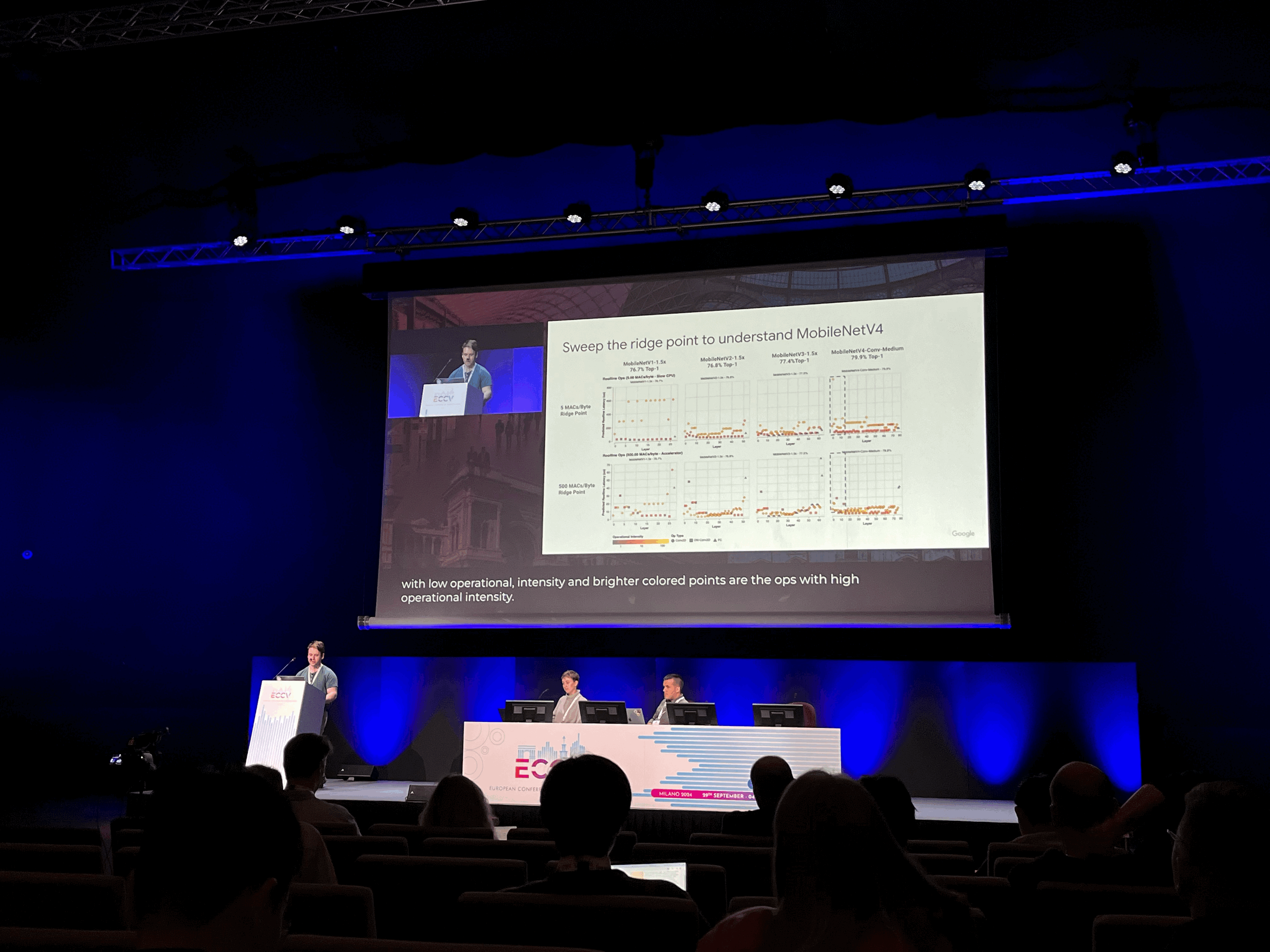
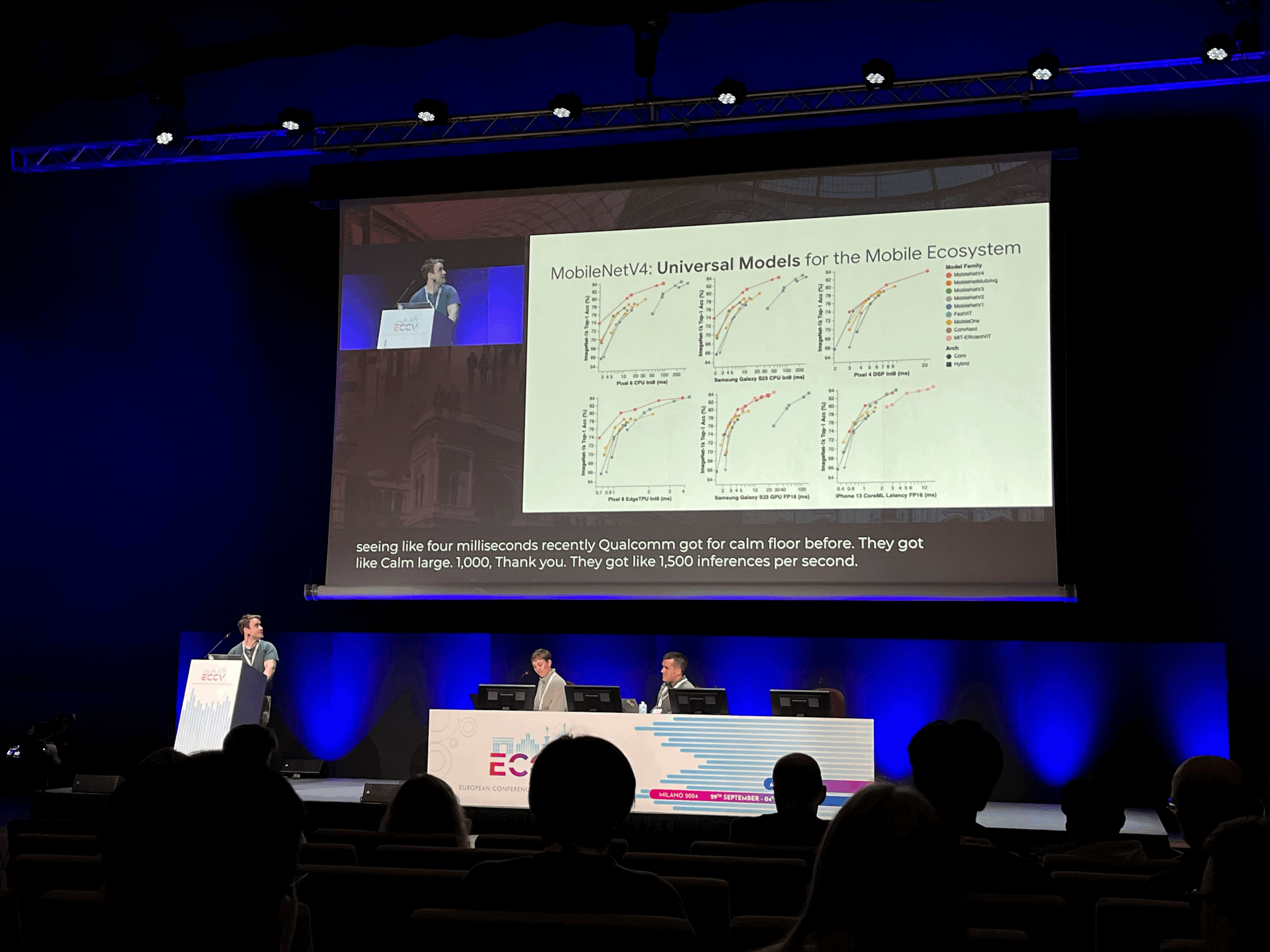

MobileNetV4: Universal Models for the Mobile Ecosystem - Google
https://eccv.ecva.net/virtual/2024/oral/482
https://www.ecva.net/papers/eccv_2024/papers_ECCV/papers/05647.pdf
+ 하드웨어에 대한 고민이 담겨서 재미있었다. (어떻게 성능을 분석할 지에 대한 방안들)
Abstract.
We present the latest generation of MobileNets: MobileNetV4 (MNv4). They feature universally-efficient architecture designs for mobile devices. We introduce the Universal Inverted Bottleneck (UIB) search block, a unified and flexible structure that merges Inverted Bottleneck (IB), ConvNext, Feed Forward Network (FFN), and a novel Extra Depthwise (ExtraDW) variant. Alongside UIB, we present Mobile MQA, an attention block for mobile accelerators, delivering a significant 39% speedup. An optimized neural architecture search (NAS) recipe is also introduced which improves MNv4 search effectiveness.
The integration of UIB, Mobile MQA and the refined NAS recipe results in a new suite of MNv4 models that are mostly Pareto optimal across mobile CPUs, DSPs, GPUs, as well as accelerators like Apple Neural Engine and Google Pixel EdgeTPU. This performance uniformity is not found in any other models tested. We introduce performance modeling and analysis techniques to explain how this performance is achieved. Finally, to further boost accuracy, we introduce a novel distillation technique. Enhanced by this technique, our MNv4-Hybrid-Large model delivers 87% ImageNet-1K accuracy, with a Pixel 8 EdgeTPU runtime of 3.8ms.

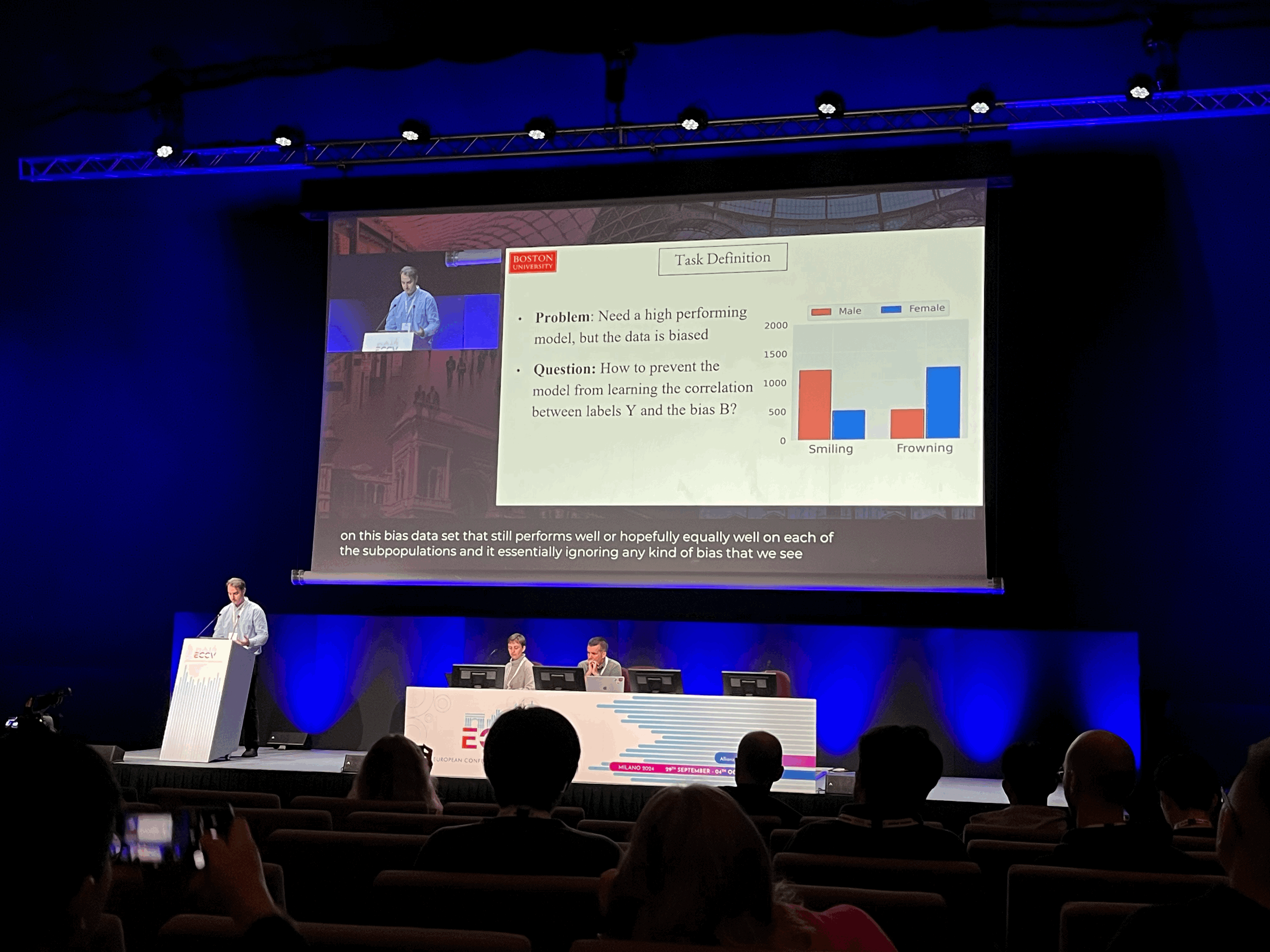

From Fake to Real: Pretraining on Balanced Synthetic Images to Prevent Spurious Correlations in Image Recognition
https://eccv.ecva.net/virtual/2024/oral/498
https://www.ecva.net/papers/eccv_2024/papers_ECCV/papers/07557.pdf


Relation DETR: Exploring Explicit Position Relation Prior for Object Detection
https://eccv.ecva.net/virtual/2024/oral/502
이 다음으로 발표하신 연구 주제가 흥미로웠는데, 시작 전에 'Still Me' 라고 하셔서 짱멋졌다.
(같은 분이 발표를 연달아서 하셨다.)

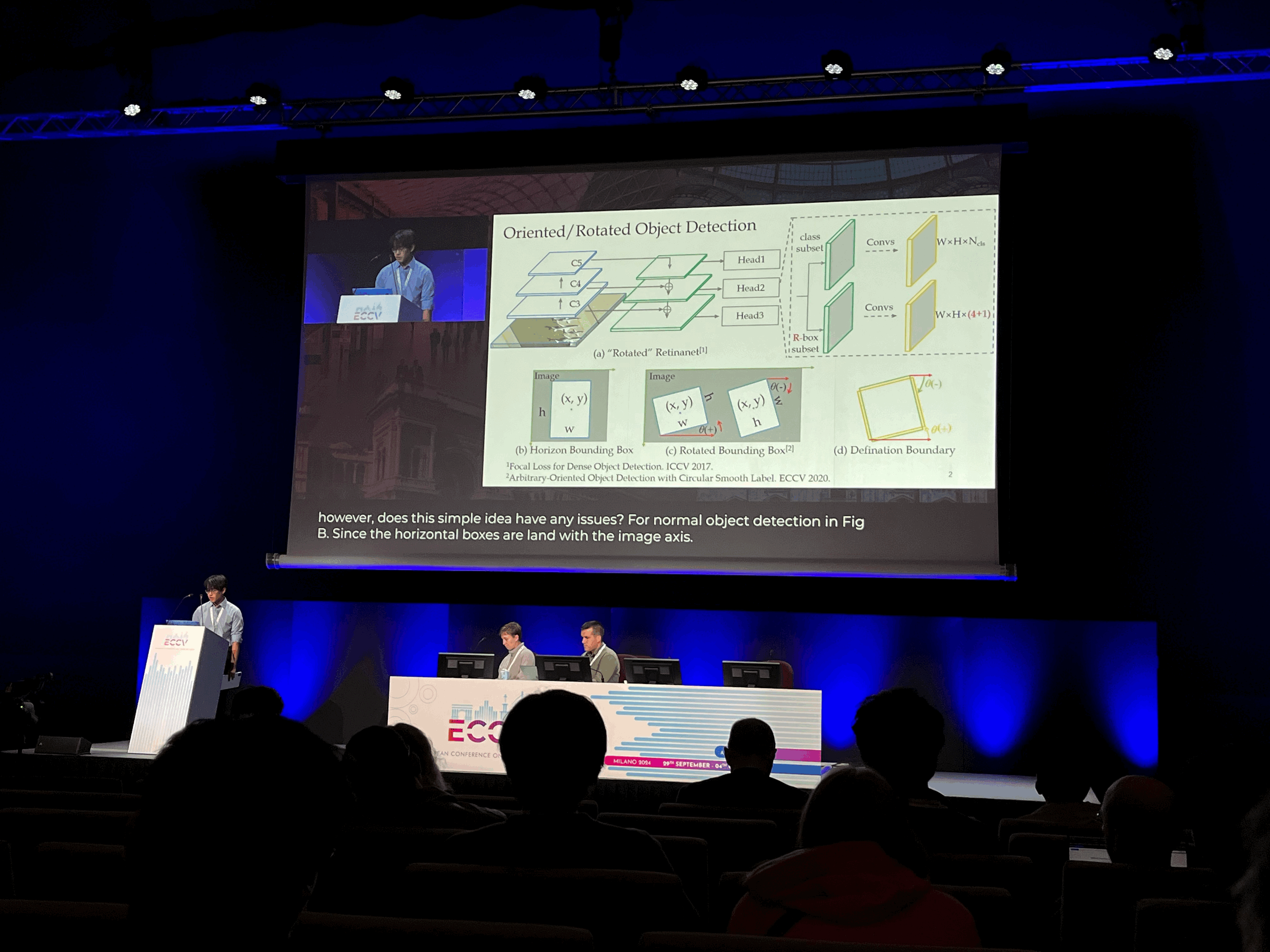








Projecting Points to Axes: Oriented Object Detection via Point-Axis Representation
https://www.ecva.net/papers/eccv_2024/papers_ECCV/papers/04051.pdf
다른 앵글을 어떻게 표현할 것인가?에 대한 아이디어가 흥미로웠다.
객체의 키 포인트들을 알아내는 것 -> object detection
X, y를 d로 바꾼다 -> direction information
Abstract.
This paper introduces the point-axis representation for oriented object detection, as depicted in aerial images in Figure 1, emphasizing its flexibility and geometrically intuitive nature with two key components: points and axes. 1) Points delineate the spatial extent and contours of objects, providing detailed shape descriptions. 2) Axes define the primary directionalities of objects, providing essential orientation cues crucial for precise detection. The point-axis representation decouples location and rotation, addressing the loss discontinuity issues commonly encountered in traditional bounding box-based approaches.
For effective optimization without introducing additional annotations, we propose the max-projection loss to supervise point set learning and the cross-axis loss for robust axis representation learning. Further, leveraging this representation, we present the Oriented DETR model, seamlessly integrating the DETR framework for precise point-axis prediction and end-to-end detection. Experimental results demonstrate significant performance improvements in oriented object detection tasks.
CLIFF: Continual Latent Diffusion for Open-Vocabulary Object Detection
https://eccv.ecva.net/virtual/2024/oral/488
- 아까 박경문 교수님 연구도 그렇고, Continual learning에 대해서 공부해보면, 더 이해가 잘 되었을 것 같다.
Abstract. Open-vocabulary object detection (OVD) utilizes image-level cues to expand the linguistic space of region proposals, thereby facilitating the detection of diverse novel classes. Recent works adapt CLIP embedding by minimizing the object-image and object-text discrepancy combinatorially in a discriminative paradigm. However, they ignore the underlying distribution and the disagreement between the image and text objective, leading to the misaligned distribution between the vision and language sub-space. To address the deficiency, we explore the advanced generative paradigm with distribution perception and propose a novel framework based on the diffusion model, coined Continual Latent Diffusion (CLIFF), which formulates a continual distribution transfer among the object, image, and text latent space probabilistically. CLIFF consists of a Variational Latent Sampler (VLS) enabling the probabilistic modeling and a Continual Diffusion Module (CDM) for the distribution transfer. Specifically, in VLS, we first establish a probabilistic object space with region proposals by estimating distribution parameters. Then, the object-centric noise is sampled from the estimated distribution to generate text embedding for OVD. To achieve this generation process, CDM con- ducts a short-distance object-to-image diffusion from the sampled noise to generate image embedding as the medium, which guides the long-distance diffusion to generate text embedding. Extensive experiments verify that CLIFF can significantly surpass state-of-the-art methods on benchmarks. The code is available at https://github.com/CUHK-AIM-Group/CLIFF.
https://github.com/CUHK-AIM-Group/CLIFF
On Calibration of Object Detectors: Pitfalls, Evaluation and Baselines
Abstract. Reliable usage of object detectors require them to be calibrated - a crucial problem that requires careful attention. Recent approaches to- wards this involve (1) designing new loss functions to obtain calibrated detectors by training them from scratch, and (2) post-hoc Temperature Scaling (TS) that learns to scale the likelihood of a trained detector to output calibrated predictions. These approaches are then evaluated based
on a combination of Detection Expected Calibration Error (D-ECE) and Average Precision. In this work, via extensive analysis and insights, we highlight that these recent evaluation frameworks, evaluation metrics, and the use of TS have notable drawbacks leading to incorrect conclu- sions. As a step towards fixing these issues, we propose a principled evaluation framework to jointly measure calibration and accuracy of object detectors. We also tailor efficient and easy-to-use post-hoc calibration approaches such as Platt Scaling and Isotonic Regression specifically for object detection task. Contrary to the common notion, our experiments show that once designed and evaluated properly, post-hoc calibrators, which are extremely cheap to build and use, are much more powerful and effective than the recent train-time calibration methods. To illustrate, D-DETR with our post-hoc Isotonic Regression calibrator outperforms the recent train-time state-of-the-art calibration method Cal-DETR by more than 7 D-ECE on the COCO dataset. Additionally, we propose improved versions of the recently proposed Localization-aware ECE and show the efficacy of our method on these metrics. Code is available at: https://github.com/fiveai/detection_calibration.
https://github.com/fiveai/detection_calibration
임팩트 있는 발표자료를 만들려면 굵은 라인을 사용하자
약간의 애니메이션으로 몰입시키기 (그래프에서 옮겨가기)
큰 목소리 · 자신감 있는 자세
사용하기 쉬움을 강조하셨다
'ArtificialIntelligence > ECCV2024' 카테고리의 다른 글
| ECCV 2024 Day3 - SAM2: Meta Technical Presentation (0) | 2024.11.18 |
|---|---|
| ECCV 2024 Day3 - Synthesia Keynote (2) | 2024.11.14 |
| ECCV 2024 DAY3 - Demo Session (7) | 2024.10.18 |
| ECCV 2024 DAY2 - Dataset Distillation Workshop (2) (2) | 2024.10.08 |
| ECCV 2024 DAY2 - Dataset Distillation Workshop (1) (0) | 2024.10.08 |