[Paper reading] DenseNet
2023. 8. 22. 12:49ㆍArtificialIntelligence/PaperReading
DenseNet

Abstract
- Recent work has shown that convolutional networks can be substantially deeper, more accurate, and efficient to train if they contain shorter connections between layers close to the input and those close to the output.
- In this paper, we embrace this observation and introduce the Dense Convolutional Network (DenseNet), which connects each layer to every other layer in a feed-forward fashion. Whereas traditional convolutional networks with L layers have L connections — one between each layer and its subsequent layer — our network has L(L+1) direct connections. For 2 each layer, the feature-maps of all preceding layers are used as inputs, and its own feature-maps are used as inputs into all subsequent layers.
- DenseNets have several compelling advantages: they alleviate the vanishing-gradient problem, strengthen feature propagation, encourage feature reuse, and substantially reduce the number of parameters.
We evaluate our proposed architecture on four highly competitive object recognition benchmark tasks (CIFAR-10, CIFAR-100, SVHN, and ImageNet).
Conclusion of Paper
- We proposed a new convolutional network architecture, which we refer to as Dense Convolutional Network (DenseNet). It introduces direct connections between any two layers with the same feature-map size. We showed that DenseNets scale naturally to hundreds of layers, while exhibiting no optimization difficulties.
- In our experiments, DenseNets tend to yield consistent improvement in accuracy with growing number of parameters, without any signs of performance degradation or overfitting. Under multiple settings, it achieved state-of-the-art results across several highly competitive datasets.
- Moreover, DenseNets require substantially fewer parameters and less computation to achieve state-of-the-art performances. Because we adopted hyperparameter settings optimized for residual networks in our study, we believe that further gains in accuracy of DenseNets may be obtained by more detailed tuning of hyperparameters and learning rate schedules.
- Whilst following a simple connectivity rule, DenseNets naturally integrate the properties of identity mappings, deep supervision, and diversified depth. They allow feature reuse throughout the networks and can consequently learn more compact and, according to our experiments, more accurate models.
- Because of their compact internal representations and reduced feature redundancy, DenseNets may be good feature extractors for various computer vision tasks that build on convolutional features.
Conclusion
장점
- Dense connectivity 설명 도입부에서 ResNet skip connection에서의 아쉬운 점을 개선한 방식을 제안하며, 왜 dense connectivity가 효과적인 방안인지 논리적으로 설명되었다. 나아가 지속적으로(일관적으로) 다양한 방면에서 ResNet과 비교하며, 내용이 전개되는 점이 이해하는데 효과적이었다.
- parameter 수가 더 적을 수 있는 근거를 제시
- 데이터셋에 대한 분석을 한 점이 새로웠다. (SVHN이 비교적 쉬운 과업이라고 추정하는 근거)
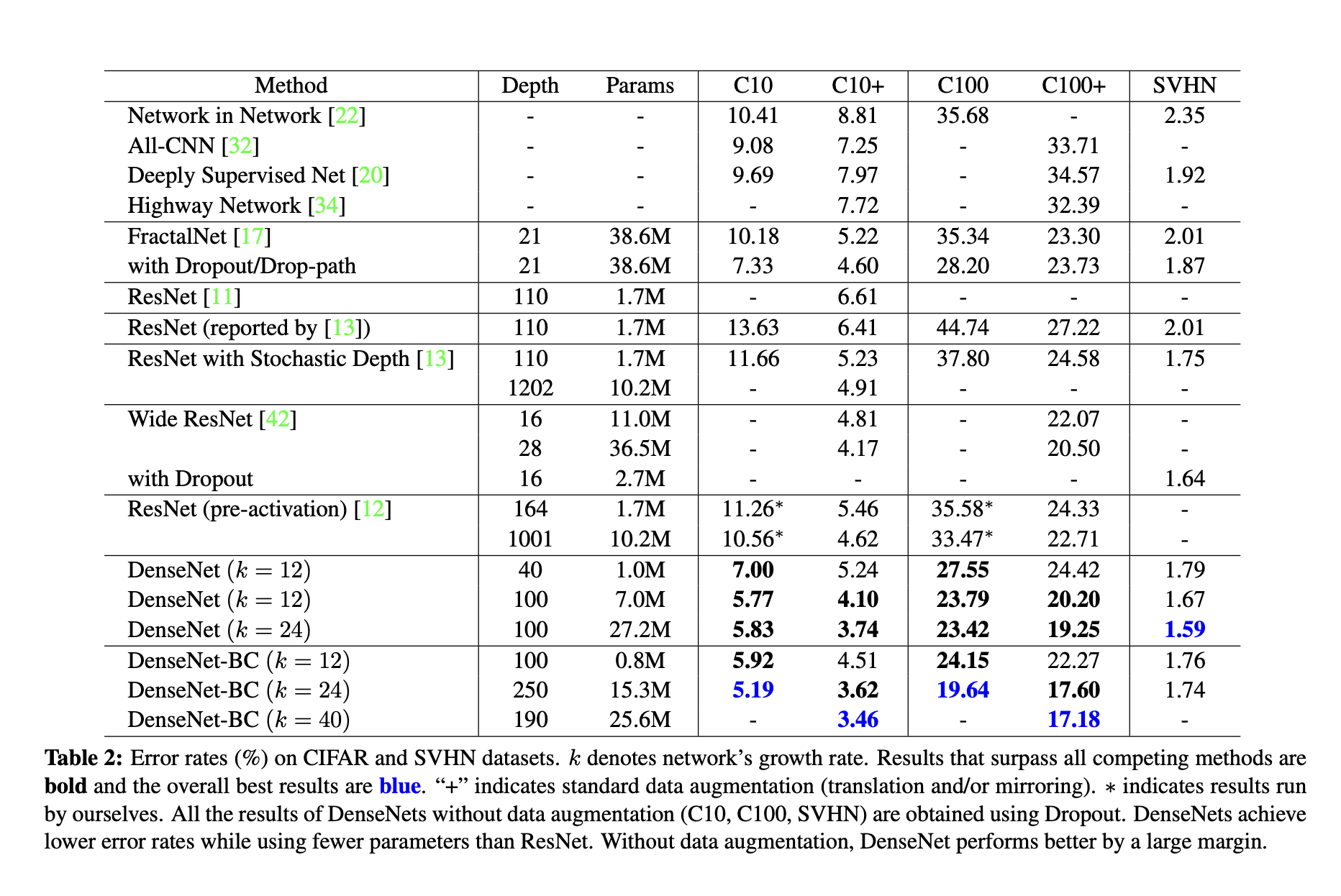
However, the 250-layer DenseNet-BC doesn’t further improve the performance over its shorter counterpart. This may be explained by that SVHN is a relatively easy task, and extremely deep models may overfit to the training set.
- Parameter를 보다 효과적으로 활용한다는 모델이라는 점
+ 다른 모델과의 성능을 비교할 때, 단순히 error를 비교하는 것에서 나아가 parameter 수를 상세히 분석함으로써, 보다 현실적이고 효과적으로 모델 분석 방법이 발전되었다고 생각한다. (동일한 모델 아키텍처 내에서도 어떤 구조가 더 params 측면에서 효과적인지) - DenseNet이 오버피팅에 취약하지 않은 이유와 더불어 오버피팅이 발생할 수 있는 상황에서 이를 해결할 수 있는 방안까지 제시한 점이 좋았다.
- The DenseNet-BC bottleneck and compression layers appear to be an effective way to counter this trend.
단점
- This suggests that DenseNets can utilize the increased representational power of bigger and deeper models. It also indicates that they do not suffer from overfitting or the optimization difficulties of residual networks.
- 이미지 데이터(CIFAR)에 대한 결과로 DenseNet은 residual network와 달리 overfitting or optimization 문제를 겪지 않을 수 있을 것이라고 판단하기는 어렵지 않을까? (근거가 부실한 것 같다.)
- DenseNets perform a similar deep supervision in an implicit fashion: a single classifier on top of the network provides direct supervision to all layers through at most two or three transition layers.
However, the loss function and gradient of DenseNets are substantially less complicated, as the same loss function is shared between all layers.
단순한 GD를 너머, 다양한 구조가 제시될 때, gradient - loss func은 어떻게 설계되어야 하는지?
- feature reuse 측면에서 단계별 heat map 그래프를 통해 구체적으로 분석한 과정이 인상깊었다.
- All layers spread their weights over many inputs within the same block. This indicates that features extracted by very early layers are, indeed, directly used by deep layers throughout the same dense block.
- The weights of the transition layers also spread their weight across all layers within the preceding dense block, indicating information flow from the first to the last layers of the DenseNet through few indirections.
- The layers within the second and third dense block consistently assign the least weight to the outputs of the transition layer (the top row of the triangles), indicating that the transition layer outputs many redundant features (with low weight on average). This is in keeping with the strong results of DenseNet-BC where exactly these outputs are compressed.
- Although the final classification layer, shown on the very right, also uses weights across the entire dense block, there seems to be a concentration towards final feature-maps, suggesting that there may be some more high-level features produced late in the network.
개선할 점 & Question
- It is worth noting that our experimental setup implies that we use hyperparameter settings that are optimized for ResNets but not for DenseNets. It is conceivable that more extensive hyper-parameter searches may further improve the performance of DenseNet on ImageNet.
- 어떻게 더 개선될 수 있는 지 함께 제시되었으면 더 좋았을 것 같다.
- Superficially, DenseNets are quite similar to ResNets:
only in that the inputs to Hl(·) are concatenated instead of summed.
However, the implications of this seemingly small modification lead to substantially different behaviors of the two network architectures. - As a direct consequence of the input concatenation, the feature-maps learned by any of the DenseNet layers can be accessed by all subsequent layers. This encourages feature reuse throughout the network, and leads to more compact models.
'ArtificialIntelligence > PaperReading' 카테고리의 다른 글
| [Paper reading] Transformers for image recognition, ViT (0) | 2023.08.28 |
|---|---|
| [Paper reading] Attention is all you need, Transformer (0) | 2023.08.25 |
| [Paper reading] GoogleNet (0) | 2023.08.18 |
| [Paper reading] ResNet (0) | 2023.08.16 |
| [Paper reading] VGGNet (0) | 2023.08.16 |