2023. 9. 5. 21:47ㆍArtificialIntelligence/2023GoogleMLBootcamp




W가 only parameter, nx dim vector.
b는 real number

loss func - single training example에 대한 error
cost func - cost of your params (전체 데이터에 대해, Parameter W, b의 평균 에러를 의미)
Gradient Descent

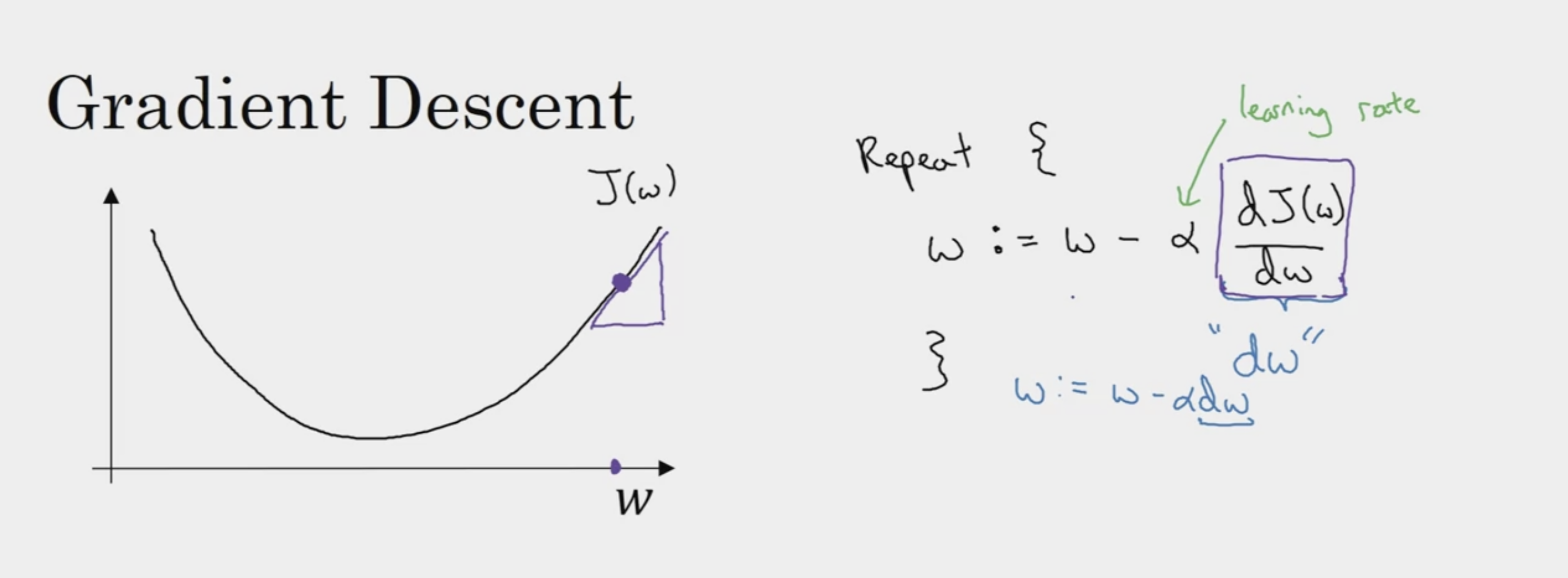
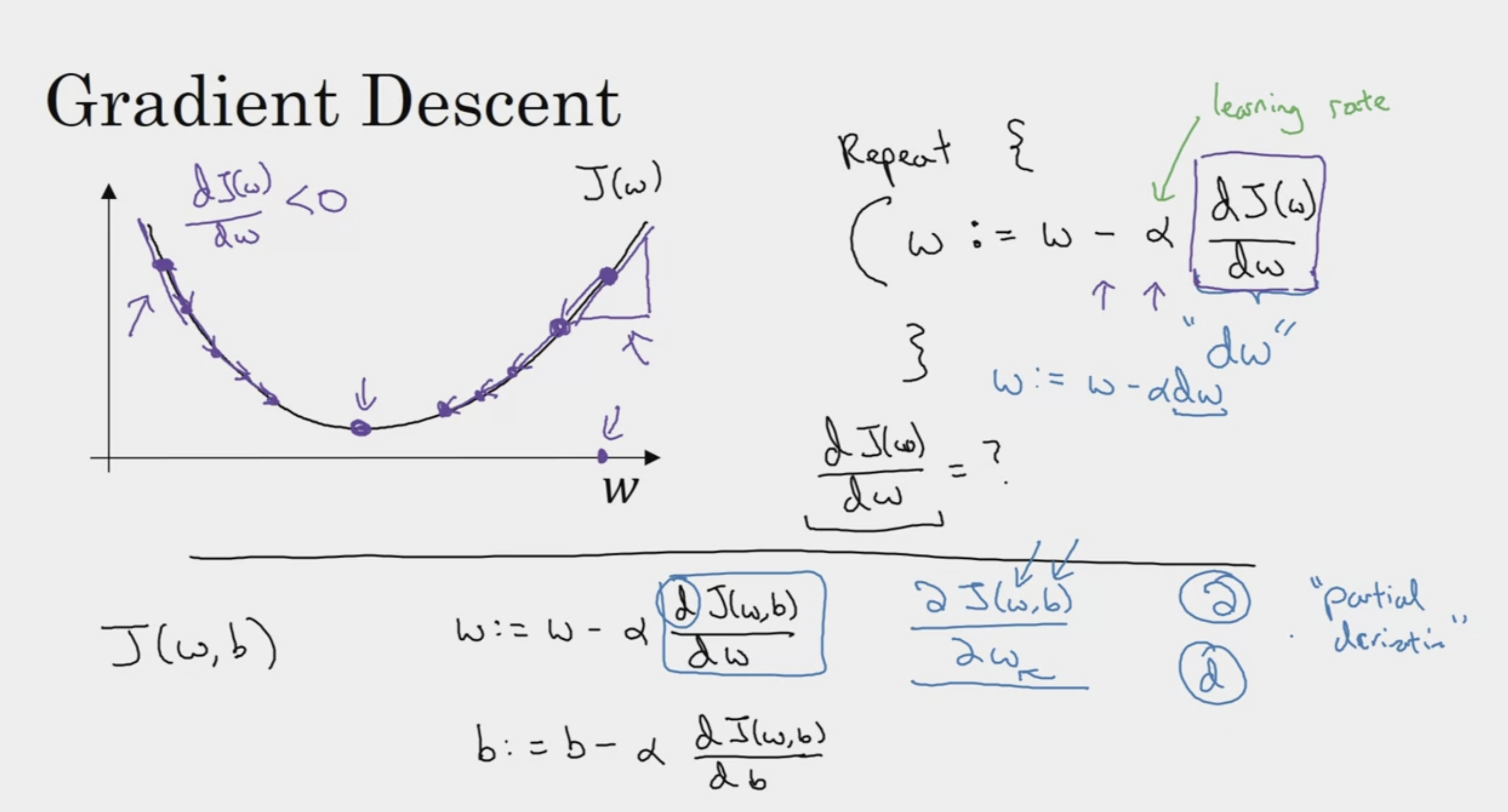
slope of the function
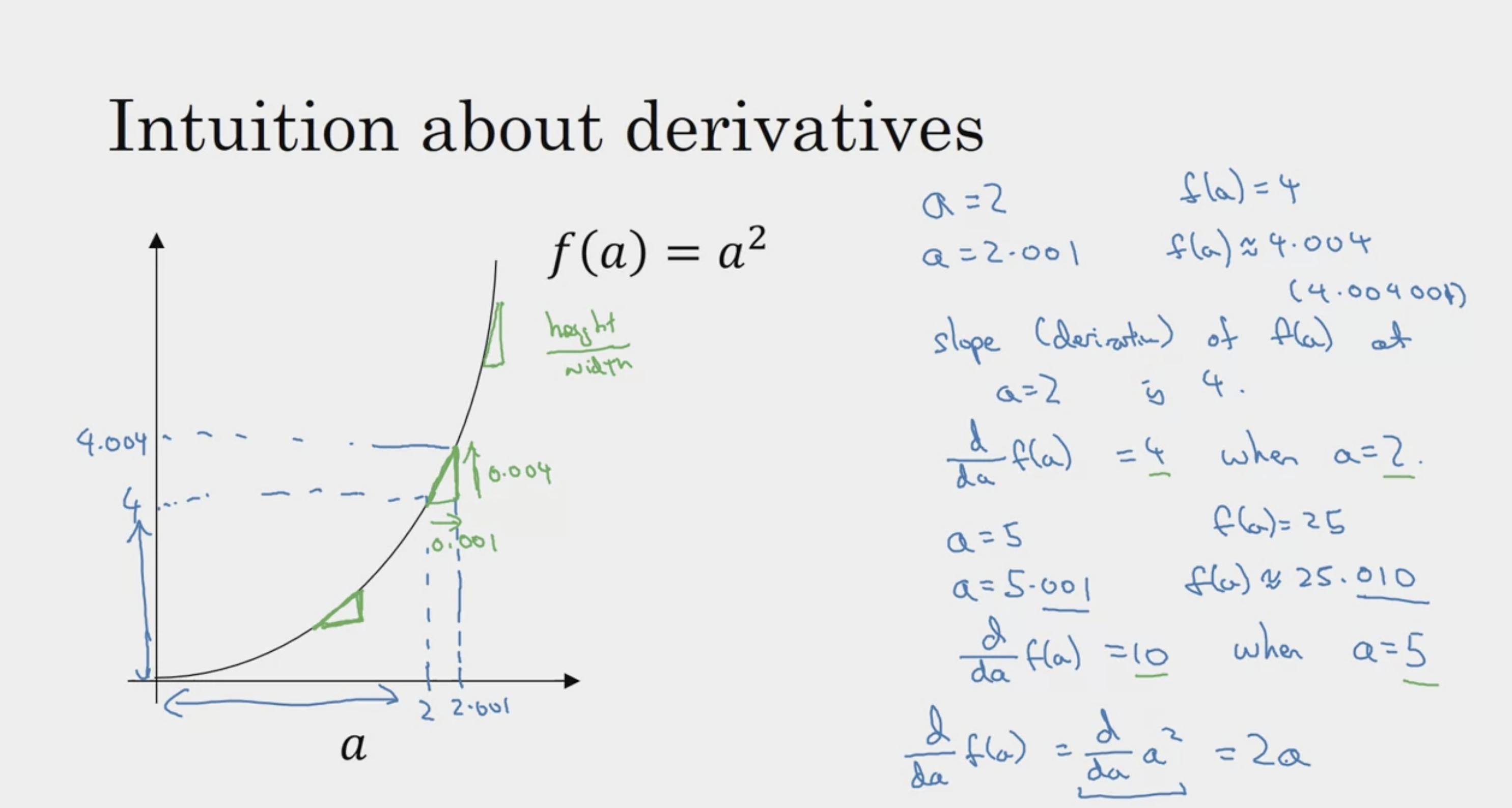
Derivatives


직선이라면 (1차 함수)
a의 값에 무관하게, 함수의 증가량은 변수 증가량의 3배
즉 3으로 미분값이 일정하다

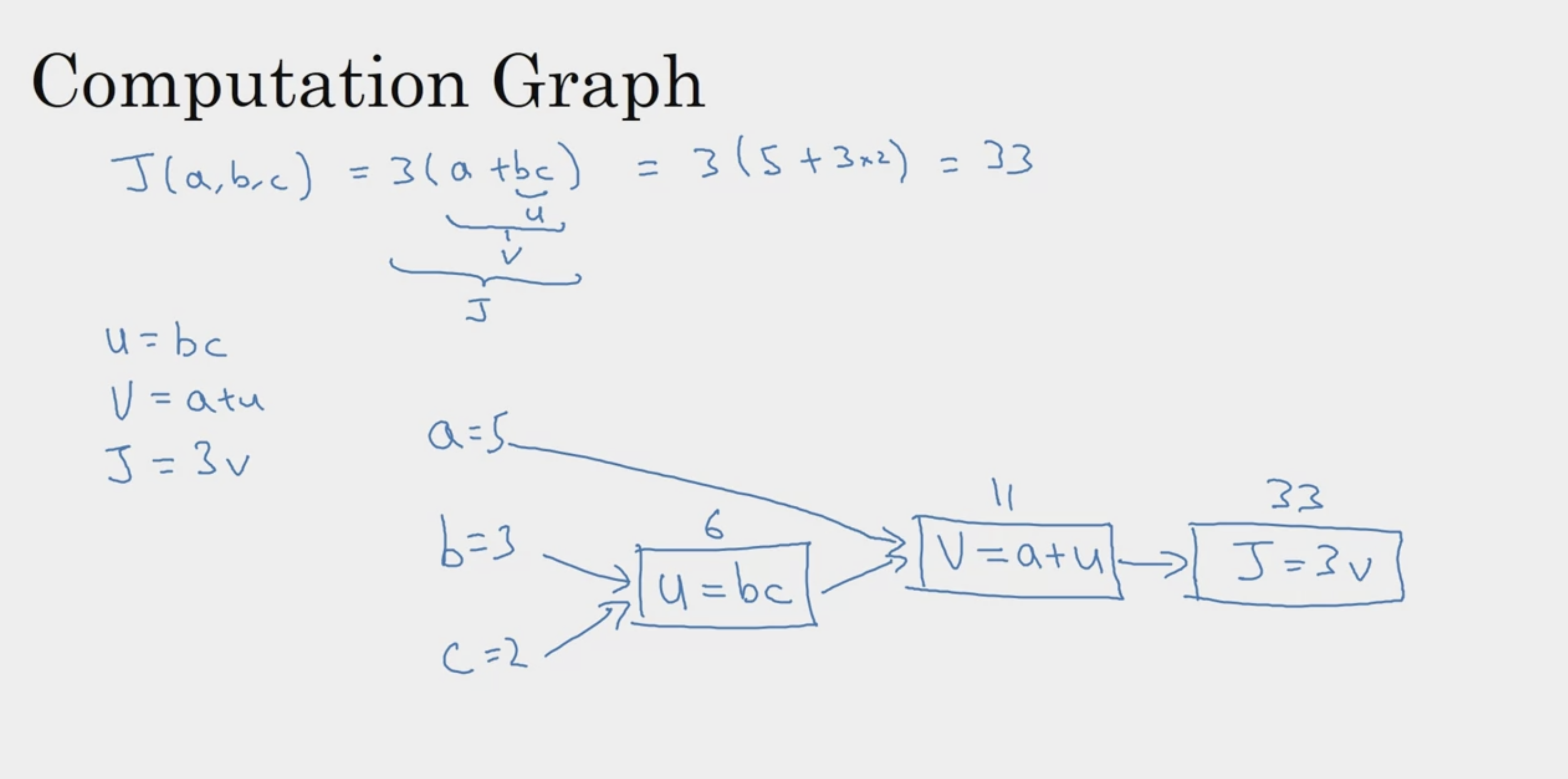
Computation Graph
Derivatives with a Computation Graph
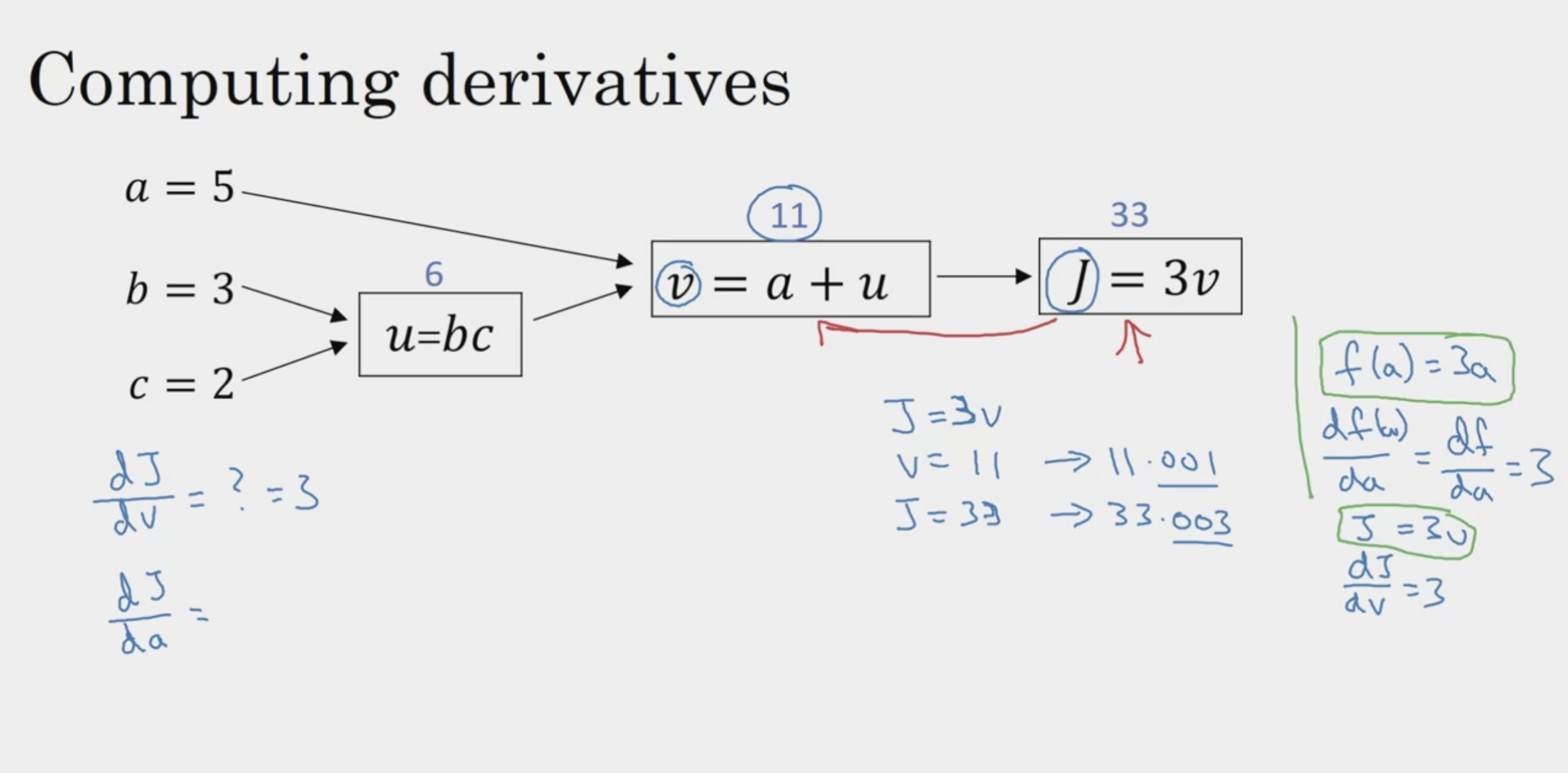



Logistic Regression Gradient Descent




Gradient Descent on m Examples


큰 data에 대해 매우 효율적으로 계산 가능! :)
Quiz 탈 락 🔥
'ArtificialIntelligence > 2023GoogleMLBootcamp' 카테고리의 다른 글
| [GoogleML] Activation Functions' Derivatives (0) | 2023.09.10 |
|---|---|
| [GoogleML] Shallow Neural Network, Vectorizing (0) | 2023.09.09 |
| [GoogleML] Chapter 1 Neural Networks and Deep Learning (0) | 2023.09.07 |
| [GoogleML] Python and Vectorization (0) | 2023.09.07 |
| [GoogleML] Introduction to Deep Learning (0) | 2023.09.05 |