2023. 9. 10. 02:59ㆍArtificialIntelligence/2023GoogleMLBootcamp
Explanation for Vectorized Implementation




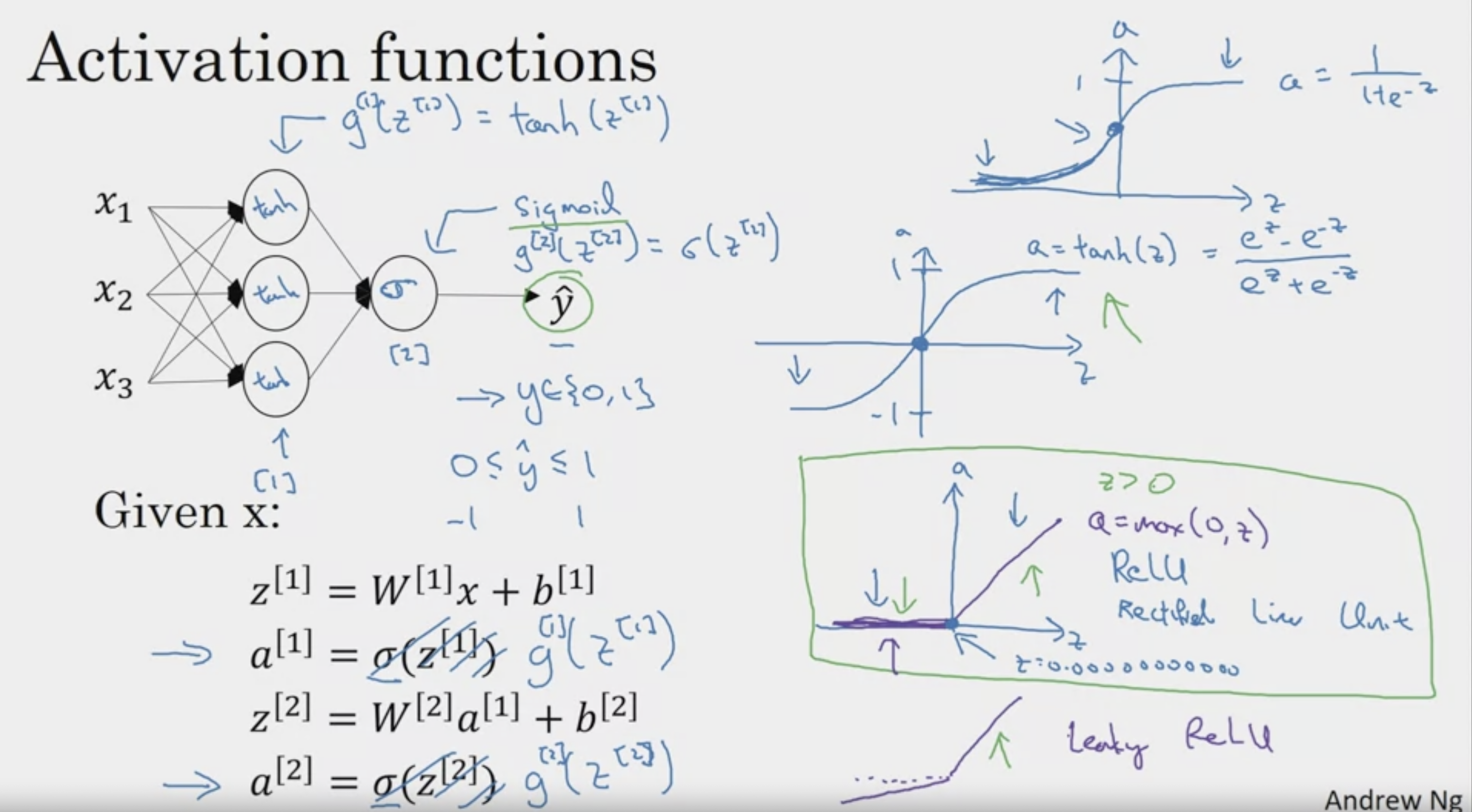
Activation Functions

tanh는 sigmoid를 shift한 func (거의 동일)
but tanh가 sigmoid보다는 조금 더 유리하다
why? -> mean이 zero에 형성
-> 통과한 이후 값들의 평균이 중앙에 분포, 더 유리 (sigmoid는 0.5)

마지막 layer에서는 sigmoid 사용
why?
y는 0 or 1
따라서 출력을 0과 1 사이로 맞추려고 tanh 보다는 sigmoid

gradient 기울기가 소멸되는 문제를 해결하기 위해
ReLU를 사용한다.
0이 되는 미분 불가능한 point에서는 0에 가까운 값을 대신 출력
어떠한 활성화 함수를 쓸 지 모르겠다면, ReLU를 써라
Leaky ReLU도 있다
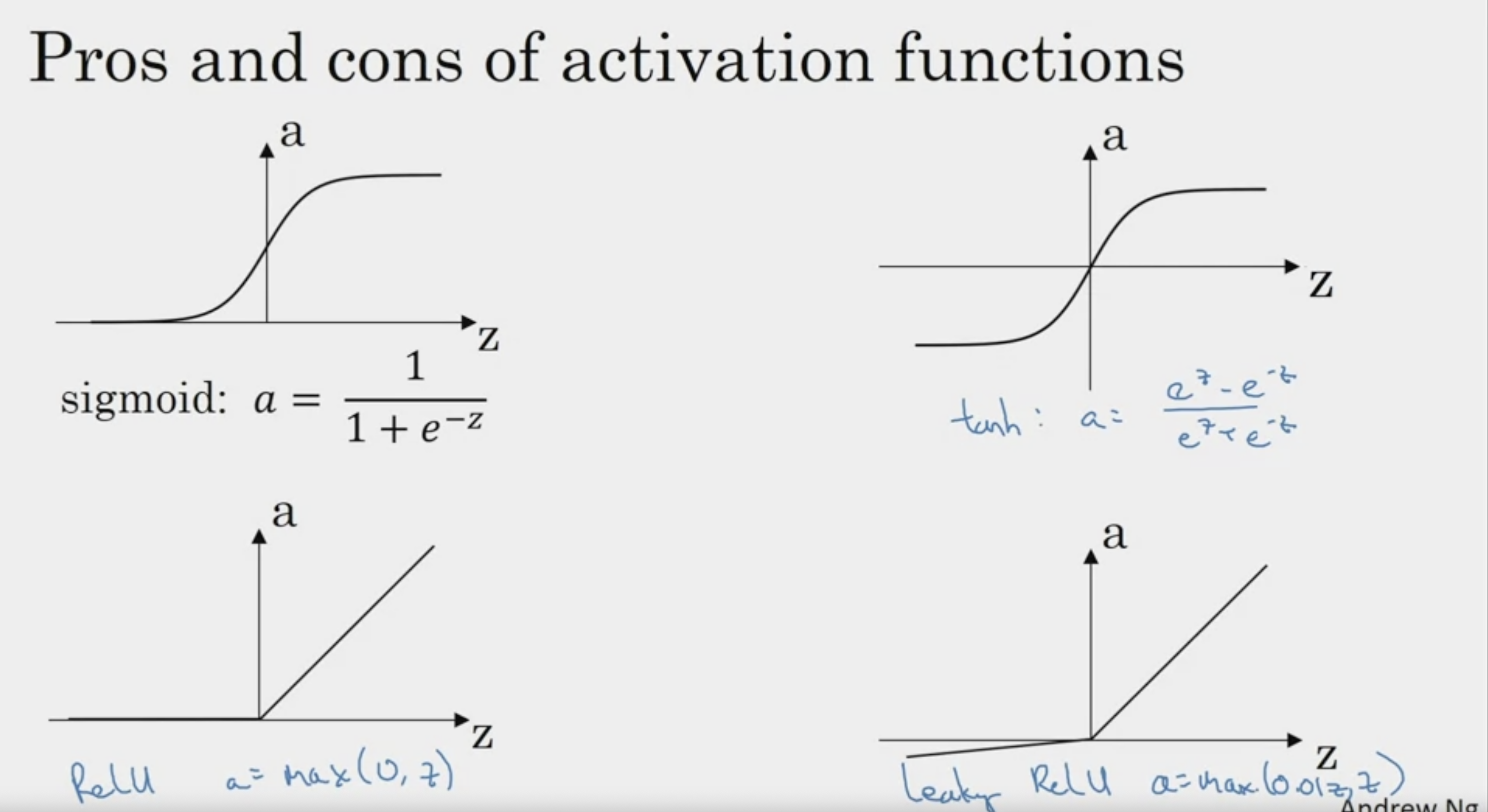
leaky ReLU 에서
a = max(0.01z, z)
이러한 수식으로 표현될 수 있다! :)
어떠한 activation func을 쓸 지 모르겠다면?
여러 함수들을 다 적용시키고, 평가해보아라
(deep하게 쌓일 경우, ReLU 추천)
Why do you need Non-Linear Activation Functions?

linear, identity func을 취한다면?
Z 활성화 함수 통과 대신에, 그냥 weighted 된 값을 다음 layer로 넘긴다면?
활성화함수가 없다면?

선형 연산의 중첩 -> 또 다른 선형 연산
층을 깊게 쌓는 것에 대한 이점이 X (layer 1과 same)
many hidden layer no more expressive

y -> real number
우리가 ReLU, tanh 등
non linear activation func을 사용하는 이유
(없다면, 직선 하나랑 같음, XOR 해결 X)
Derivatives of Activation Functions
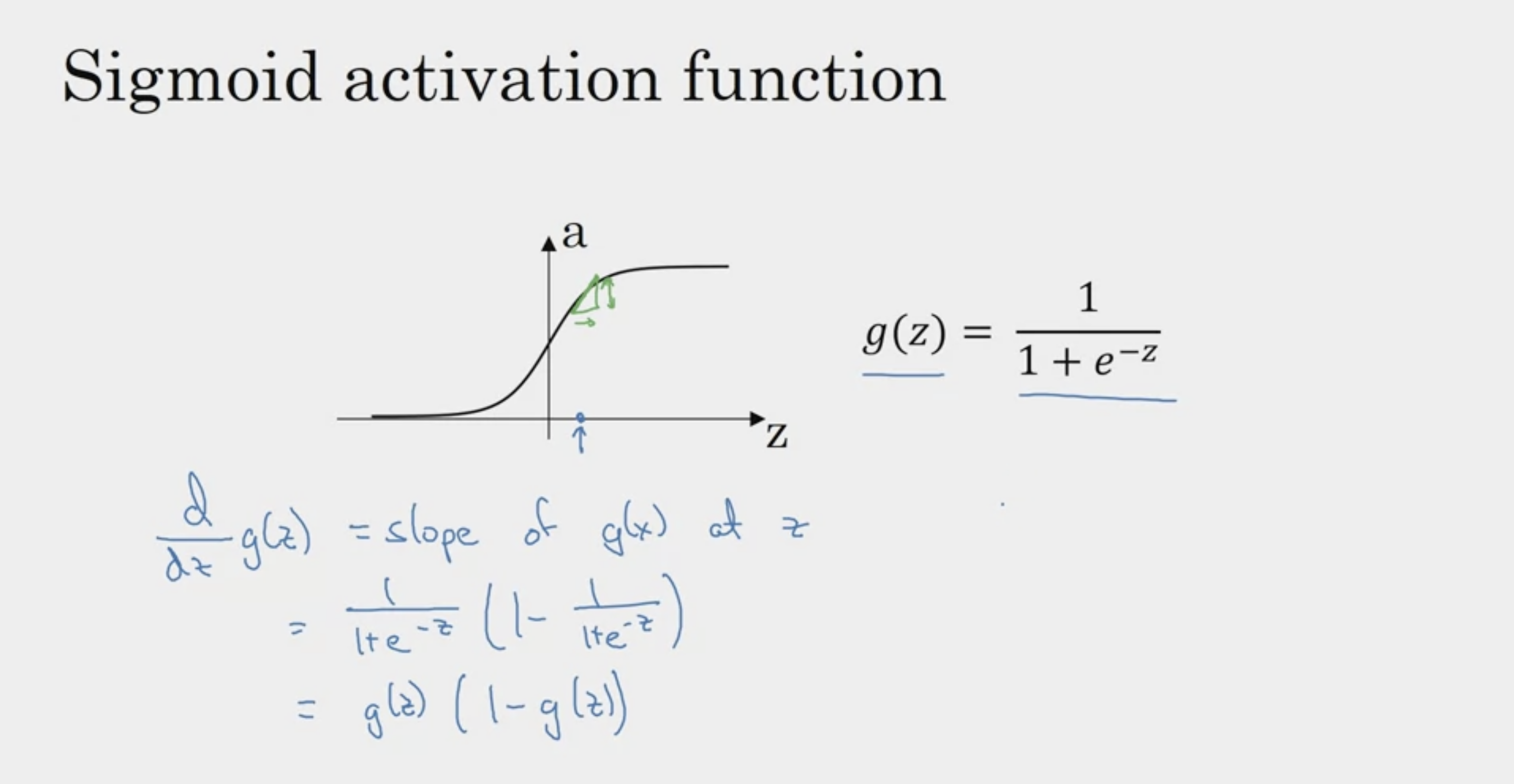
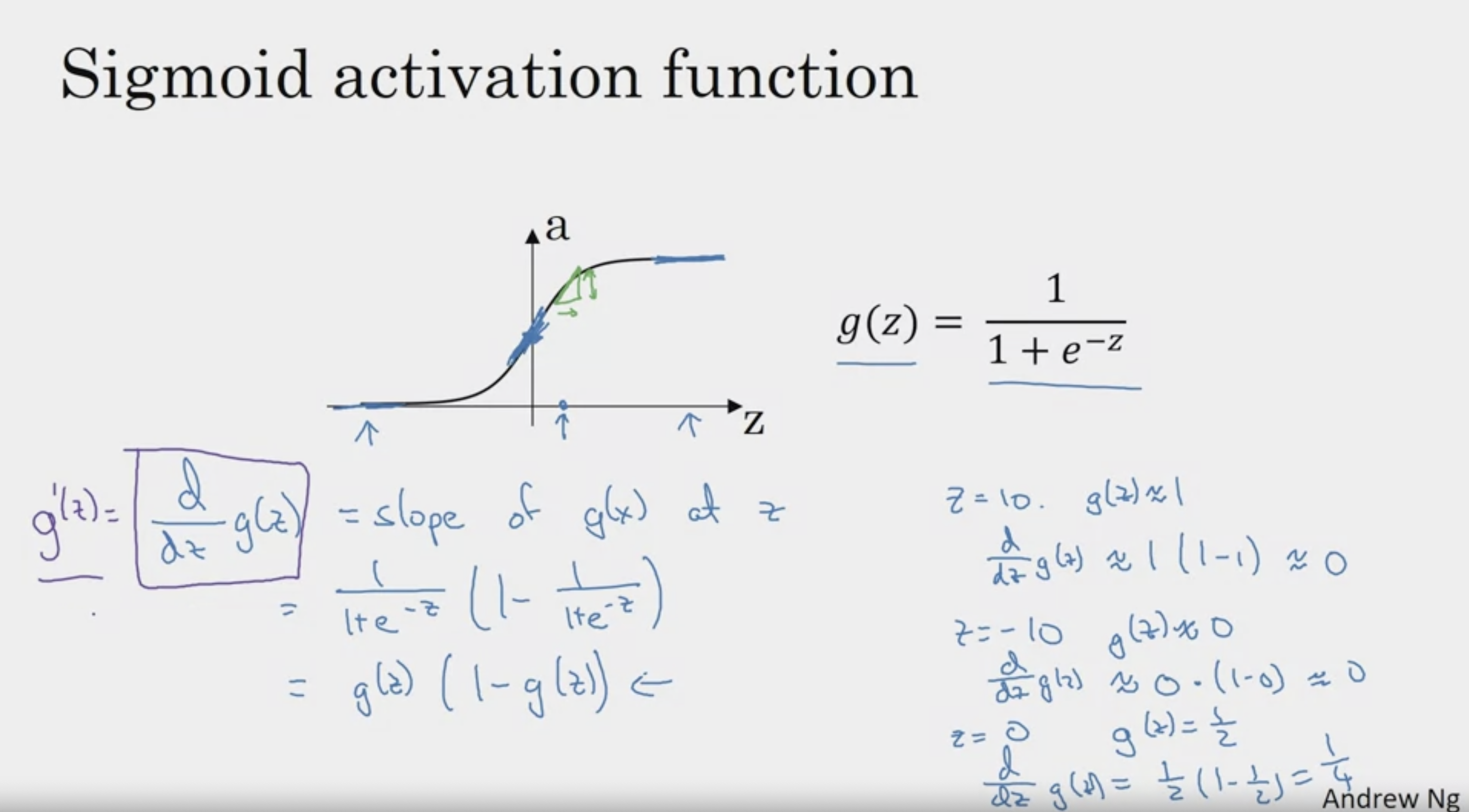
g(z) = a 로 치환하여
a ( 1 - a )로 표현하는 경우도 많다
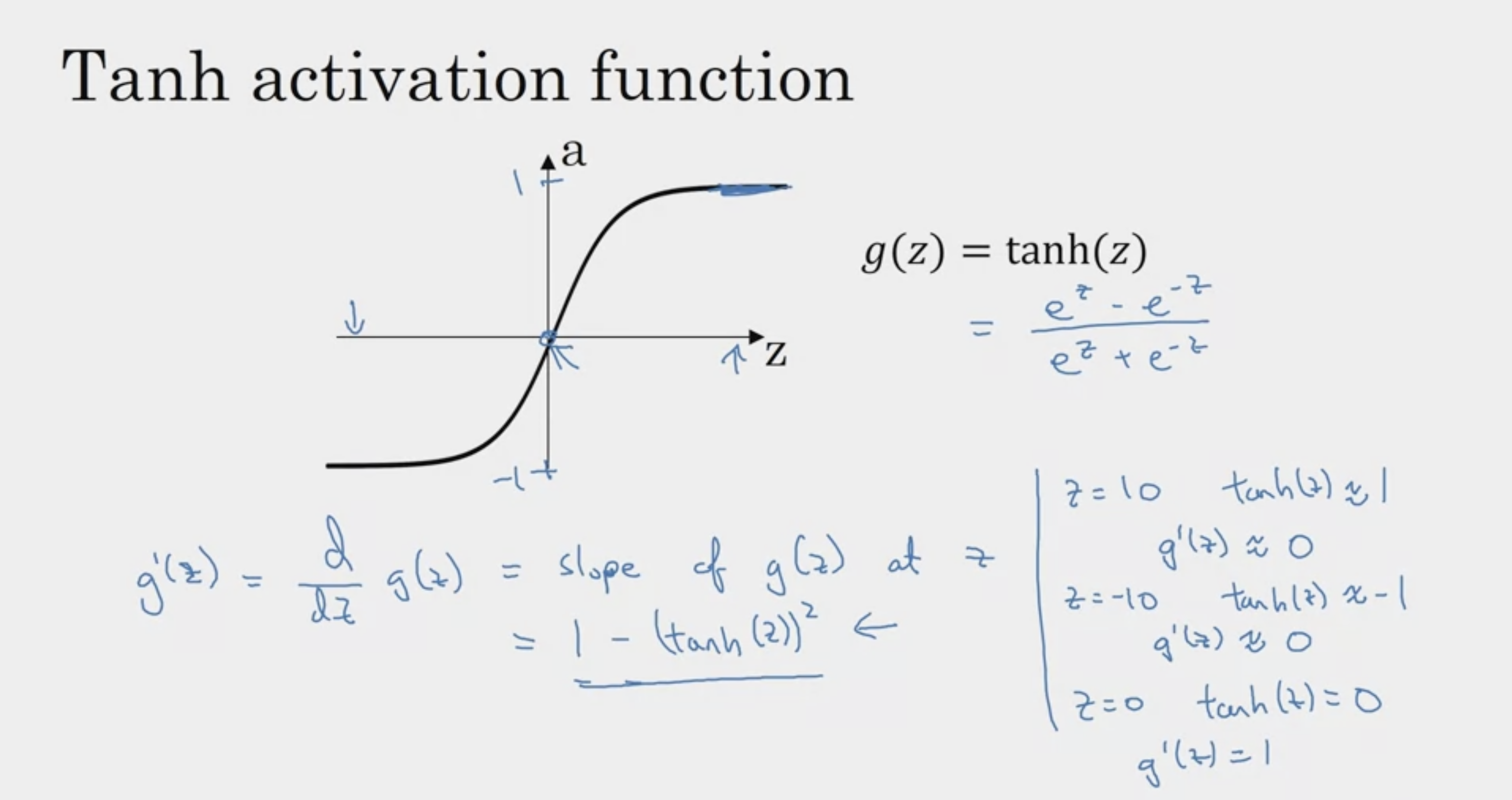
간단한 값을 대입하여 파악하는 방법
좋은 것 같다! :)
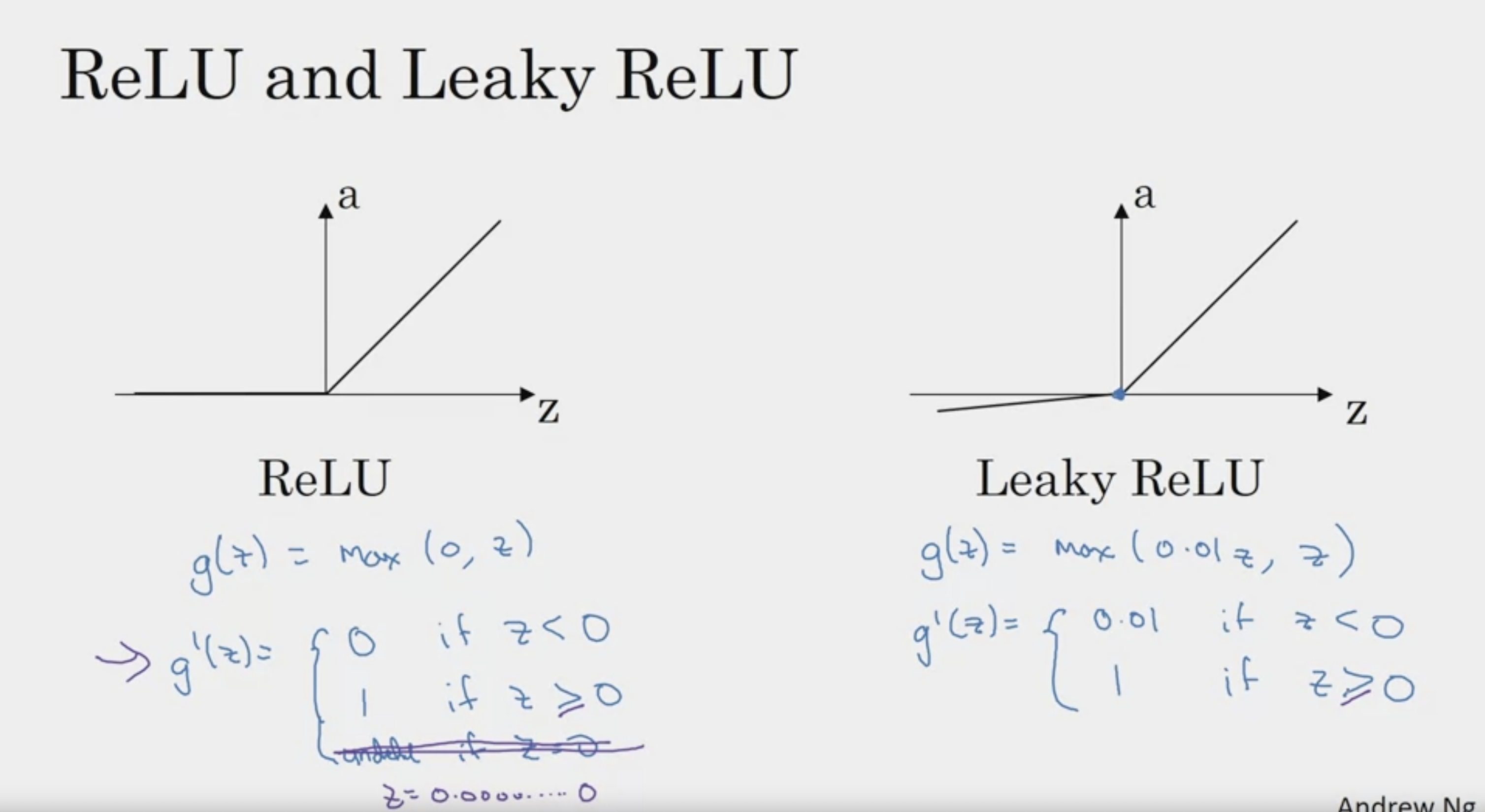
컴퓨터로 구현할 때에는 수치적인 오차가 미세하게 발생 가능
따라서 if z = 0 대신, 부등호로 표현하는 것이 올바르다
Gradient Descent for Neural Networks



Random Initialization

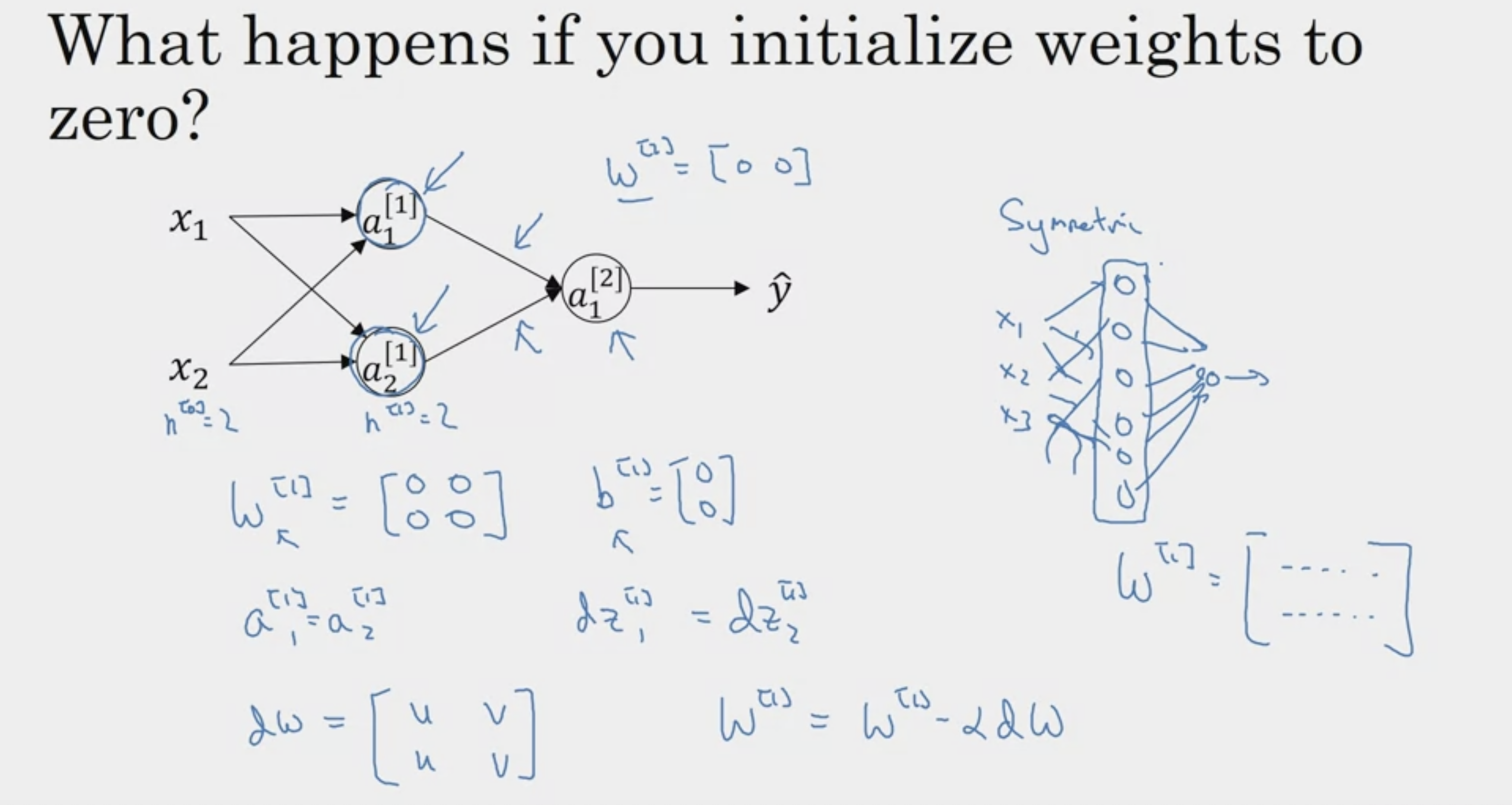
아무리 많은 유닛을 써도, 동일하게 update (유용X)
따라서 random initialization이 중요하다
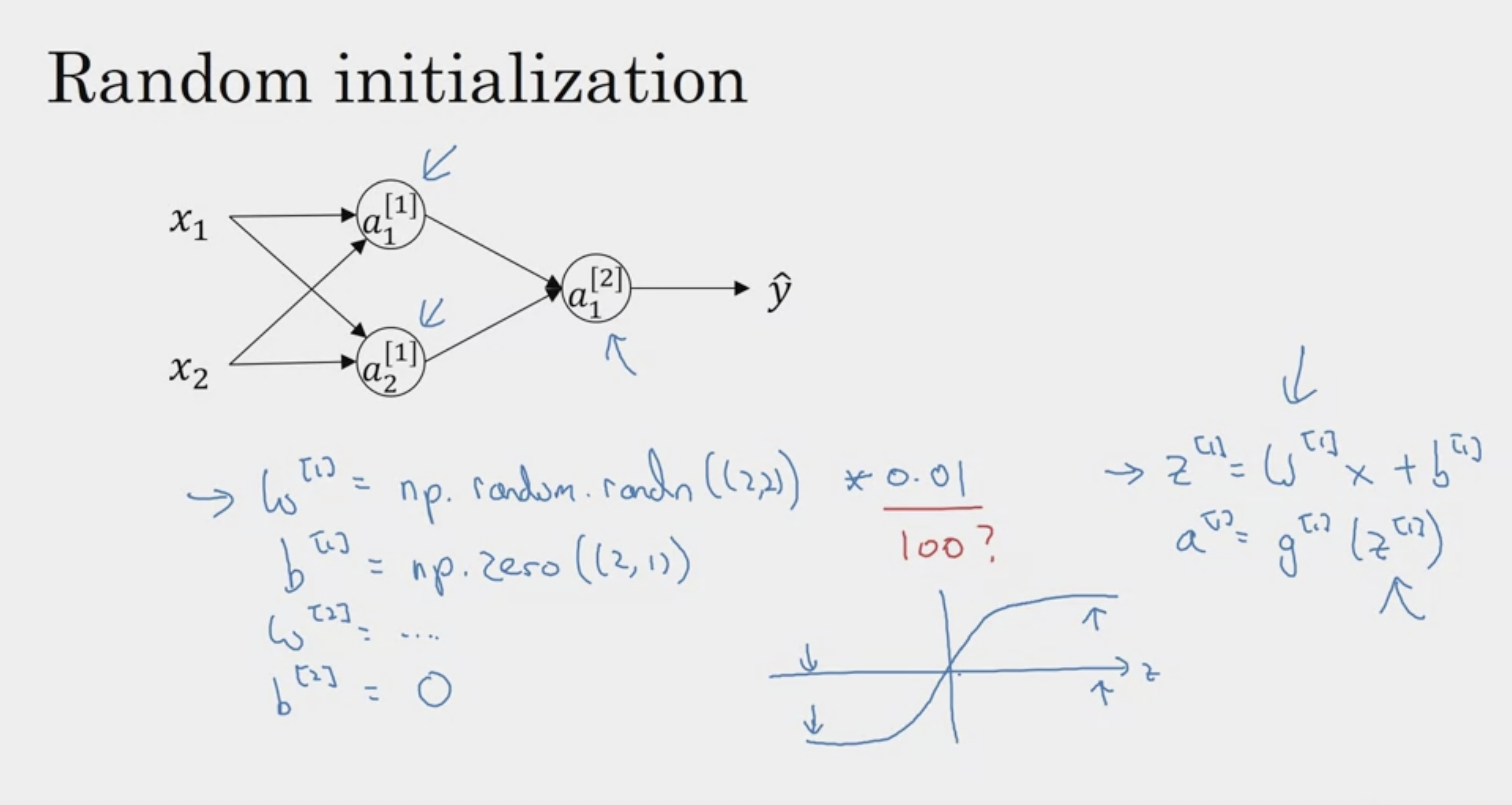
왜 0.01같은 작은 수를 곱하나?
weight를 초기화할 때에는 매우 작은 수로 주는 것이 좋다.
왜냐하면 tanh에서, 0에 가까운 작은 값일수록
gradient가 많이 발생하기 때문에! :)
'ArtificialIntelligence > 2023GoogleMLBootcamp' 카테고리의 다른 글
| [GoogleML] Neural Networks and Deep Learning 수료 (0) | 2023.09.12 |
|---|---|
| [GoogleML] Deep Neural Network (0) | 2023.09.11 |
| [GoogleML] Shallow Neural Network, Vectorizing (0) | 2023.09.09 |
| [GoogleML] Chapter 1 Neural Networks and Deep Learning (0) | 2023.09.07 |
| [GoogleML] Python and Vectorization (0) | 2023.09.07 |