2023. 9. 13. 13:40ㆍArtificialIntelligence/2023GoogleMLBootcamp
Normalizing Inputs


Vanishing / Exploding Gradients
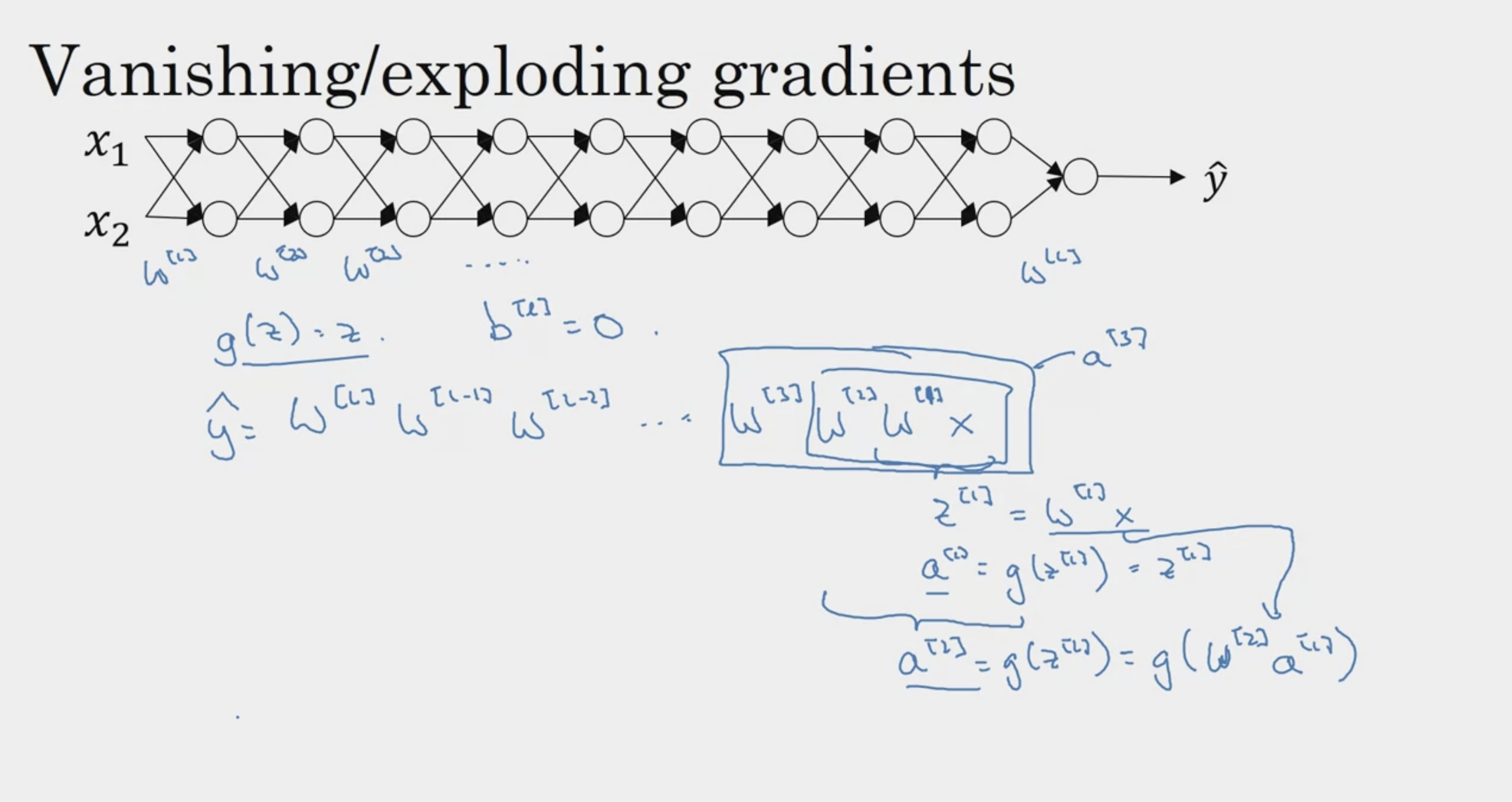
겹겹이 쌓인 W -> weights

1.5 -> 지수적으로 증가 (gradient 폭발)
0.5 -> 지수적으로 감소 (gradient vanishing)
layer가 깊게 쌓일수록, 학습이 어려워지는 문제
이를 해결하기 위한 웨이트 초기화
Weight Initialization for Deep Networks

weight init 중요하다
gradient가 폭발하거나 사라지게 하지 않기 위해서
Numerical Approximation of Gradients


단방향 / 양방향 grad 계산

Gradient Checking


이 수식은 어떤 값을 확인하라는거지 . . ? 잘 모르겠다.
cos 유사도도 아닌 것 같고,
편미분 값이랑 원래 함수 미분 값 차이를 두 norm의 합으로 나눈다. . ?
Gradient Checking Implementation Notes

1. 미분 값을 계산하는 연산은 computational하게 비싼 연산, 학습 과정에서는 확인하지 말자
2. 버그가 없는지, 수식 제대로 작성된건지 확인하기
3. 규제 항이 있는 것은 아닌지
4. dropout 적용하면 cost func 제대로 계산하기 매우 어렵다 -> keepprob으로 drop 꺼두고 확인 -> 이후에 조정
5. random initialization (0에 가까울 때만 backpropagation이 제대로 동작할 수 도 있다.)
'ArtificialIntelligence > 2023GoogleMLBootcamp' 카테고리의 다른 글
| [GoogleML] Adam Optimizer (0) | 2023.09.20 |
|---|---|
| [GoogleML] Optimization Algorithms (0) | 2023.09.20 |
| [GoogleML] Regularizing Neural Network (0) | 2023.09.12 |
| [GoogleML] Setting up Machine Learning (0) | 2023.09.12 |
| [GoogleML] Neural Networks and Deep Learning 수료 (0) | 2023.09.12 |