[PIM] Processing-in-memory: A workload-driven perspective
2024. 5. 21. 14:17ㆍComputerScience/ProcessingInMemory
Processing-in-memory: A workload-driven perspective (IBM, 2019)
https://ieeexplore.ieee.org/document/8792187
Processing-in-memory: A workload-driven perspective
Many modern and emerging applications must process increasingly large volumes of data. Unfortunately, prevalent computing paradigms are not designed to efficiently handle such large-scale data: The energy and performance costs to move this data between the
ieeexplore.ieee.org

- Many modern and emerging applications must process increasingly large volumes of data. Unfortunately, prevalent computing paradigms are not designed to efficiently handle such large-scale data: The energy and performance costs to move this data between the memory subsystem and the CPU now dominate the total costs of computation. This forces system architects and designers to fundamentally rethink how to design computers.
- Processing-in-memory(PIM) is a computing paradigm that avoids most data movement costs by bringing computation to the data. New opportunities in modern memory systems are enabling architectures that can perform varying degrees of processing inside the memory subsystem.
- However, many practical system-level issues must be tackled to construct PIM architectures, including enabling workloads and programmers to easily take advantage of PIM. This article examines three key domains of work toward the practical construction and widespread adoption of PIM architectures.
- First, we describe our work on systematically identifying opportunities for PIM in real applications and quantify potential gains for popular emerging applications (e.g., machine learning, data analytics, genome analysis).
- Second, we aim to solve several key issues in programming these applications for PIM architectures.
- Third, we describe challenges that remain for the widespread adoption of PIM.
Introduction
- A wide range of application domains have emerged as computing platforms of all types have become more ubiquitous in society. Many of these modern and emerging applications must now process very large datasets. For example, an object classification algorithm in an augmented reality application typically trains on millions of example images and video clips and performs classification on real-time high-definition video streams. In order to process meaningful information from the large amounts of data, applications turn to artificial intelligence (AI), or machine learning, and data analytics to methodically mine through the data and extract key properties about the dataset.
- Due to the increasing reliance on manipulating and mining through large sets of data, these modern applications greatly overwhelm the data storage and movement resources of a modern computer. In a contemporary computer, the main memory [consisting of dynamic random-access memory (DRAM)] is not capable of performing any operations on data.
- As a result, to perform any operation on data that is stored in memory, the data needs to be moved from the memory to the CPU via the memory channel, a pin-limited off-chip bus (e.g., conventional double data rate, or DDR, memories use a 64-bit memory channel [10–12]).
- To move the data, the CPU must issue a request to the memory controller, which then issues commands across the memory channel to the DRAM module containing the data. The DRAM module then reads and returns the data across the memory channel, and the data moves through the cache hierarchy before being stored in a CPU cache. The CPU can operate on the data only after the data is loaded from the cache into a CPU register.
- 컴퓨터 구조에서 배우던 전통적인 Flow
- Unfortunately, for modern and emerging applications, the large amounts of data that need to move across the memory channel create a large data movement bottleneck in the computing system [13, 14]. The data movement bottleneck incurs a heavy penalty in terms of both performance and energy consumption [13–20].
- First, there is a long latency and significant energy involved in bringing data from DRAM.
- Second, it is difficult to send a large number of requests to memory in parallel, in part because of the narrow width of the memory channel.
- Third, despite the costs of bringing data into memory, much of this data is not reused by the CPU, rendering the caching either highly inefficient or completely unnecessary [5, 21], especially for modern workloads with very large datasets and random access patterns.
- Today, the total cost of computation, in terms of performance and in terms of energy, is dominated by the cost of data movement for modern data-intensive workloads such as machine learning and data analytics
- The high cost of data movement is forcing architects to rethink the fundamental design of computer systems. As data-intensive applications become more prevalent, there is a need to bring computation closer to the data, instead of moving data across the system to distant compute units. Recent advances in memory design enable the opportunity for architects to avoid unnecessary data movement by performing processing-in-memory (PIM), also known as near-data processing. (PNM, Processing near Memory, https://news.samsungsemiconductor.com/kr/삼반뉴스-ep-5-메모리가-연산까지-하게-된-사연은-memcon-2023/)
- The idea of performing PIM has been proposed for at least four decades [26–36], but earlier efforts were not widely adopted due to the difficulty of integrating processing elements for computation with DRAM. Innovations such as three-dimensional (3-D)- stacked memory dies that combine a logic layer with DRAM layers [5, 37–40], the ability to perform logic operations using memory cells themselves inside a memory chip [18, 20, 41–49], and the emergence of potentially more computation-friendly resistive memory technologies [50–61] provide new opportunities to embed general- purpose computation directly within the memory.
- While PIM can allow many data-intensive applications to avoid moving data from memory to the CPU, it introduces new challenges for system architects and programmers. In this article, we examine two major areas of challenges and discuss solutions that we have developed for each challenge.
- First, programmers need to be able to identify opportunities in their applications where PIM can improve their target objectives (e.g., application performance, energy consumption). As we discuss in Section 3, whether to execute part or all of an application in memory depends on: 1) architectural constraints, such as area and energy limitations, and the type of logic implementable within memory; and 2) application properties, such as the intensities of computation and memory accesses, and the amount of data shared across different functions.
To solve this first challenge, we have developed toolflows that help the programmer to systematically determine how to partition work between PIM logic (i.e., processing elements on the memory side) and the CPU in order to meet all architectural design constraints and maximize targeted benefits. - Second, system architects and programmers must establish efficient interfaces and mechanisms that allow programs to easily take advantage of the benefits of PIM.
In particular, the processing logic inside memory does not have quick access to important mechanisms required by modern programs and systems, such as cache coherence and address translation, which programmers rely on for software development productivity.
To solve this second challenge, we develop a series of interfaces and mechanisms that are designed specifically to allow programmers to use PIM in a way that preserves conventional programming models.
- First, programmers need to be able to identify opportunities in their applications where PIM can improve their target objectives (e.g., application performance, energy consumption). As we discuss in Section 3, whether to execute part or all of an application in memory depends on: 1) architectural constraints, such as area and energy limitations, and the type of logic implementable within memory; and 2) application properties, such as the intensities of computation and memory accesses, and the amount of data shared across different functions.
- In providing a series of solutions to these two major challenges, we address many of the fundamental barriers that have prevented PIM from being widely adopted, in a programmer-friendly way. We find that a number of future challenges remain against the adoption of PIM, and we discuss them briefly in Section 6. We hope that our work inspires researchers to address these and other future challenges, and that both our work and future works help to enable the widespread commercialization and usage of PIM-based computing systems.
Overview of PIM
- The costs of data movement in an application continue to increase significantly as applications process larger data sets. PIM provides a viable path to eliminate unnecessary data movement by bringing part or all of the computation into the memory. In this section, we briefly examine key enabling technologies behind PIM and how new advances and opportunities in memory design have brought PIM significantly closer to realization.
2.1 Initial push for PIM
- Proposals for PIM architectures extend back as far as the 1960s. Stone’s Logic-in-Memory computer is one of the earliest PIM architectures, in which a distributed array of memories combine small processing elements with small amounts of RAM to perform computation within the memory array [36].
- Between the 1970s and the early 2000s, a number of subsequent works propose different ways to integrate computation and memory, which we broadly categorize into two families of work. In the first family, which includes NON-VON [35], Computational RAM [27, 28], EXECUBE [31], Terasys [29], and IRAM [34], architects add logic within DRAM to perform data-parallel operations. In the second family of works, such as Active Pages [33], FlexRAM [30], Smart Memories [32], and DIVA [26], architects propose more versatile substrates that tightly integrate logic and reconfigurability within DRAM itself to increase flexibility and the available compute power.
- Unfortunately, many of these works were hindered by the limitations of existing memory technologies, which prevented the practical integration of logic in or near the memory.
2.2 New opportunities in modern memory systems
- Due to the increasing need for large memory systems by modern applications, DRAM scaling is being pushed to its practical limits [101–104]. It is becoming more difficult to increase the density [101, 105–107], reduce the latency [107–112], and decrease the energy consumption [101, 113, 114] of conventional DRAM architectures.
- In response, memory manufacturers are actively developing two new approaches for main memory system design, both of which can be exploited to overcome prior barriers to implementing PIM architectures.
- 기존 main memory 구조의 한계 개선 -> PIM 구조의 구현 가능성
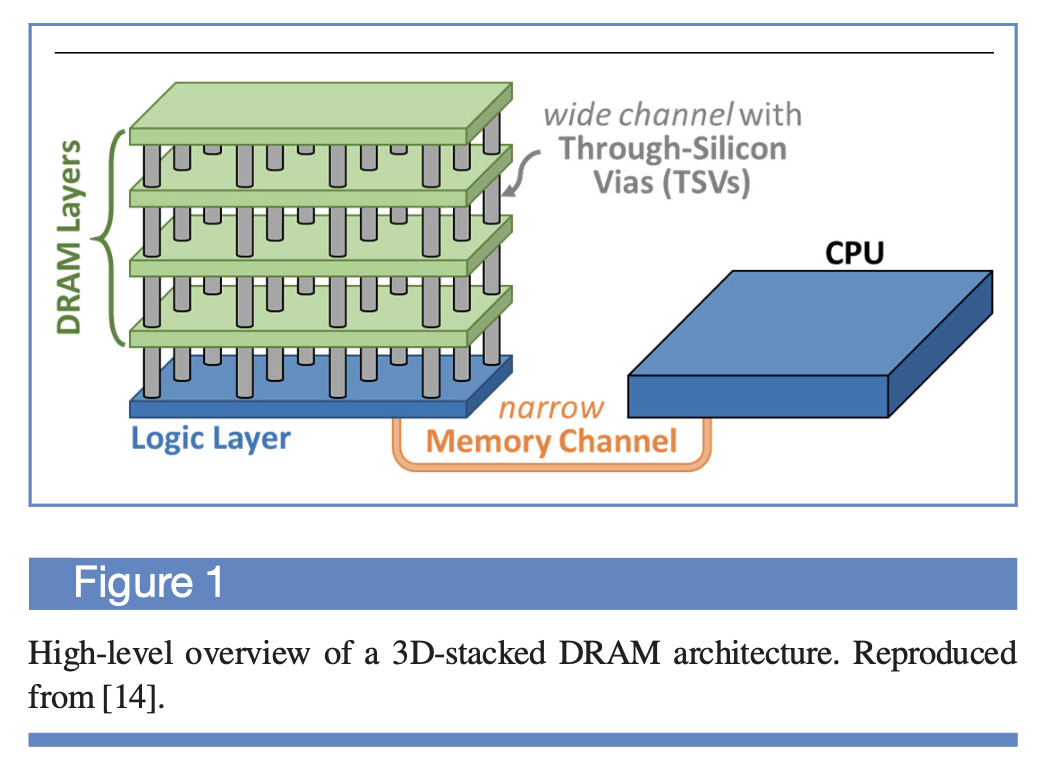
- The first major innovation is 3D-stacked memory [5, 37–40]. In a 3D-stacked memory, multiple layers of memory (typically DRAM) are stacked on top of each other, as shown in Figure 1. These layers are connected together using vertical through-silicon vias (TSVs) [38, 39].
- With current manufacturing process technologies, thousands of TSVs can be placed within a single 3D-stacked memory chip. The TSVs provide much greater internal memory bandwidth than the narrow memory channel. Examples of 3D-stacked DRAM available commercially include High-Bandwidth Memory (HBM) [37, 38], Wide I/O [115], Wide I/O 2 [116], and the Hybrid Memory Cube (HMC) [40].
- In addition to the multiple layers of DRAM, a number of prominent 3D-stacked DRAM architectures, including HBM and HMC, incorporate a logic layer inside the chip [37, 38, 40]. The logic layer is typically the bottommost layer of the chip and is connected to the same TSVs as the memory layers. The logic layer provides a space inside the DRAM chip where architects can implement functionality that interacts with both the processor and the DRAM cells.
- Currently, manufacturers make limited use of the logic layer, presenting an opportunity for architects to implement new PIM logic in the available area of the logic layer. We can potentially add a wide range of computational logic (e.g., general-purpose cores, accelerators, reconfigurable architectures) in the logic layer, as long as the added logic meets area, energy, and thermal dissipation constraints.
- The second major innovation is the use of byte-addressable resistive nonvolatile memory (NVM) for the main memory subsystem. In order to avoid DRAM scaling limitations entirely, researchers and manufacturers are developing new memory devices that can store data at much higher densities than the typical density available in existing DRAM manufacturing process technologies. Manufacturers are exploring at least three types of emerging NVMs to augment or replace DRAM at the main memory layer:
- 1) phase-change memory (PCM) [50–56];
- 2) magnetic RAM (MRAM) [57, 58];
- 3) metal-oxide resistive RAM (RRAM) or memristors [59–61].
- All three of these NVM types are expected to provide memory access latencies and energy usage that are competitive with or close enough to DRAM, while enabling much larger capacities per chip and nonvolatility in main memory.
- NVMs present architects with an opportunity to redesign how the memory subsystem operates. While it can be difficult to modify the design of DRAM arrays due to the delicacy of DRAM manufacturing process technologies as we approach scaling limitations, NVMs have yet to approach such scaling limitations.
- As a result, architects can potentially design NVM memory arrays that integrate PIM functionality. A promising direction for this functionality is the ability to manipulate NVM cells at the circuit level in order to perform logic operations using the memory cells themselves. A number of recent works have demonstrated that NVM cells can be used to perform a complete family of Boolean logic operations [41–46], similar to such operations that can be performed in DRAM cells.

2.3 Two approaches: Processing-near-memory vs. processing-using-memory
- Many recent works take advantage of the memory technology innovations that we discuss in Section 2.2 to enable PIM. We find that these works generally take one of two approaches, which are summarized in Table 1:
1) processing-near-memory or 2) processing-using-memory. - Processing-near-memory involves adding or integrating PIM logic (e.g., accelerators, very small in- order cores, reconfigurable logic) close to or inside the memory. Many of these works place PIM logic inside the logic layer of 3D-stacked memories or at the memory controller, but recent advances in silicon interposers (in-package wires that connect directly to the through-silicon vias in a 3D-stacked chip) also allow for separate logic chips to be placed in the same die package as a 3D-stacked memory while still taking advantage of the TSV bandwidth.
- In contrast, processing-using-memory makes use of intrinsic properties and operational principles of the memory cells and cell arrays themselves, by inducing interactions between cells such that the cells and/or cell arrays can perform computation. Prior works show that processing-using-memory is possible using static RAM (SRAM) [63, 76, 100], DRAM [17–20, 47–49, 80, 87, 118], PCM [41], MRAM [44–46], or RRAM/memristive [42, 43, 88, 92–99] devices. Processing-using-memory architectures enable a range of different functions, such as bulk copy and data initialization [17, 19, 63], bulk bitwise operations (e.g., a complete set of Boolean logic operations) [18, 41, 44–49, 63, 80, 106–108, 118], and simple arithmetic operations (e.g., addition, multiplication, implication).
2.4 Challenges to the adoption of PIM
- In order to build PIM architectures that are adopted and readily usable by most programmers, there are a number of challenges that need to be addressed. In this article, we discuss two of the most significant challenges facing PIM.
- First, programmers need to be able to identify what portions of an application are suitable for PIM, and architects need to understand the constraints imposed by different substrates when designing PIM logic. We address this challenge in Section 3.
- Second, once opportunities for PIM have been identified and PIM architectures have been designed, programmers need a way to extract the benefits of PIM without having to resort to complex programming models. We address this challenge in Section 4. While these two challenges represent some of the largest obstacles to widespread adoption for PIM, a number of other important challenges remain, which we discuss briefly in Section 6.
Identifying opportunities for PIM in applications
- In order to decide when to use PIM, we must first understand which types of computation can benefit from being moved to memory. The opportunities for an application to benefit from PIM depend on the constraints of the target architecture and the properties of the application.
3-2. Choosing what to execute in memory
- After the constraints on what type of hardware can potentially be implemented in memory are determined, the properties of the application itself are a key indicator of whether portions of an application benefit from PIM. A naive assumption may be to move highly memory-intensive applications completely to PIM logic. However, we find that there are cases where portions of these applications still benefit from remaining on the CPU. For example, many proposals for PIM architectures add small general-purpose cores near memory (which we call PIM cores). While PIM cores tend to be ISA-compatible with the CPU, and can execute any part of the application, they cannot afford to have large, multilevel cache hierarchies or execution logic that is as complex as the CPU, due to area, energy, and thermal constraints. PIM cores often have no or small caches, restricting the amount of temporal locality they can exploit, and no sophisticated aggressive out-of-order or superscalar execution logic, limiting the PIM cores’ abilities to extract instruction-level parallelism. As a result, portions of an application that are either compute-intensive or cache-friendly should remain on the larger, more sophisticated CPU cores [16, 21–24, 75].
- We find that in light of these constraints, it is important to identify which portions of an application are suitable for PIM. We call such portions PIM targets. While PIM targets can be identified manually by a programmer, the identification would require significant programmer effort along with a detailed understanding of the hardware tradeoffs between CPU cores and PIM cores. For architects who are adding custom PIM logic (e.g., fixed-function accelerators, which we call PIM accelerators) to memory, the tradeoffs between CPU cores and PIM accelerators may not be known before determining which portions of the application are PIM targets, since the PIM accelerators are tailored for the PIM targets.
- To alleviate the burden of manually identifying PIM targets, we develop a systematic toolflow for identifying PIM targets in an application [16, 22–24]. This toolflow uses a system that executes the entire application on the CPU to evaluate whether each PIM target meets the constraints of the system under consideration. For example, when we evaluate workloads for consumer devices, we use hardware performance counters and our energy model to identify candidate functions that could be PIM targets. A function is a PIM target candidate in a consumer device if it meets the following conditions:
- 1) It consumes the most energy out of all functions in the workload since energy reduction is a primary objective in consumer workloads.
- 2) Its data movement consumes a significant fraction (e.g., more than 20%) of the total workload energy to maximize the potential energy benefits of off- loading to PIM.
- 3) It is memory-intensive (i.e., its last-level cache misses per kilo instruction, or MPKI, is greater than 10 [122–125]), as the energy savings of PIM is higher when more data movement is eliminated.
- 4) Data movement is the single largest component of the function’s energy consumption.
- We then check if each candidate function is amenable to PIM logic implementation using two criteria. First, we discard any PIM targets that incur any performance loss when run on simple PIM logic (i.e., PIM core, PIM accelerator). Second, we discard any PIM targets that require more area than is available in the logic layer of 3D-stacked memory. Note that for pre-built PIM architectures with fixed PIM logic, we instead discard any PIM targets that cannot be executed on the existing PIM logic.
- While our toolflow was initially designed to identify PIM targets for consumer devices [16], the toolflow can be modified to accommodate any other hardware constraints. For example, in our work on reducing the cost of cache coherence in PIM architectures [22–24], we consider the amount of data sharing (i.e., the total number of cache lines that are read concurrently by the CPU and by PIM logic). In that work, we eliminate any potential PIM target that would result in a high amount of data sharing if the target were offloaded to a PIM core, as this would induce a large amount of cache coherence traffic between the CPU and PIM logic that would counteract the data movement savings (see Section 4.2).
'ComputerScience > ProcessingInMemory' 카테고리의 다른 글
| [Pin] Encoding Memory Visualization (2) | 2024.10.22 |
|---|---|
| [Pin] CoreBPE Memory Tracing by pinatrace (4) | 2024.10.15 |
| [PIM] CPU/DPU Programming Code Review (5) | 2024.07.16 |
| [PIM] HEAM: Hashed Embedding Acceleration Using Processing-In-Memory (0) | 2024.06.25 |
| [PIM] Benchmarking a New Paradigm: An Experimental Analysis of a Real Processing-in-Memory Architecture (0) | 2024.05.17 |