[PIM] HEAM: Hashed Embedding Acceleration Using Processing-In-Memory
2024. 6. 25. 00:14ㆍComputerScience/OperatingSystem
HEAM: Hashed Embedding Acceleration Using Processing-In-Memory
https://arxiv.org/abs/2402.04032
HEAM : Hashed Embedding Acceleration using Processing-In-Memory
In today's data centers, personalized recommendation systems face challenges such as the need for large memory capacity and high bandwidth, especially when performing embedding operations. Previous approaches have relied on DIMM-based near-memory processin
arxiv.org
Abstract
- In today’s data centers, personalized recommendation systems face challenges of large memory capacity requirements and high memory bandwidth demand, especially for embedding operations. Previous approaches have relied on DIMM-based near-memory processing techniques or introduced 3D-stacked DRAM to address memory-bound issues. However, these solutions fall short when dealing with the expanding size of personalized recommendation systems.
- Recommendation models have grown to sizes exceeding tens of terabytes, making them challenging to run efficiently on traditional single-node inference servers. Although various algorithmic methods have been proposed to reduce embedding table capacity, they often result in increased memory access or inefficient utilization of memory resources.
- This paper introduces HEAM, a heterogeneous memory architecture that integrates 3D-stacked DRAM with DIMM to accelerate recommendation systems in which compositional embedding is utilized a technique to reduce the size of embedding tables.
- The architecture is organized into a three-tier memory hierarchy consisting of conventional DIMM, 3D-stacked DRAM with a base die-level Processing-In-Memory (PIM), and lookup tables inside bank group-level PIM. This setup is specifically designed to accommodate the unique aspects of compositional embedding, such as temporal locality and embedding table capacity. This design effectively reduces bank access, improves access efficiency, and enhances overall throughput, resulting in 6.2× speedup and 58.9% energy savings compared to the baseline.
Introduction
- Personalized recommendation system serves as an essential technology of various companies such as Meta [1], YouTube [2] and Netflix [3]. Recently, deep learning based recommendation systems have emerged as a pivotal technology for improving the accuracy of predicting user preferred content, thereby contributing to enhanced profitability for these companies. These advanced recommendation systems currently contribute substantially to the computational workload of the data center. Recent reports indicate that approximately 80% of data center resources are dedicated to the inference process of recommendation systems. Recommendation models use dense features for user information and sparse features for item specifics through embedding operations.
- Following feature interactions, multi-layer perceptron (MLP) layers generate click-through-rate (CTR) predictions, estimating the likelihood of user clicks on recommended items. In large-scale data centers that extensively utilize embeddings, the embedding operation often becomes the primary factor influencing overall system performance.
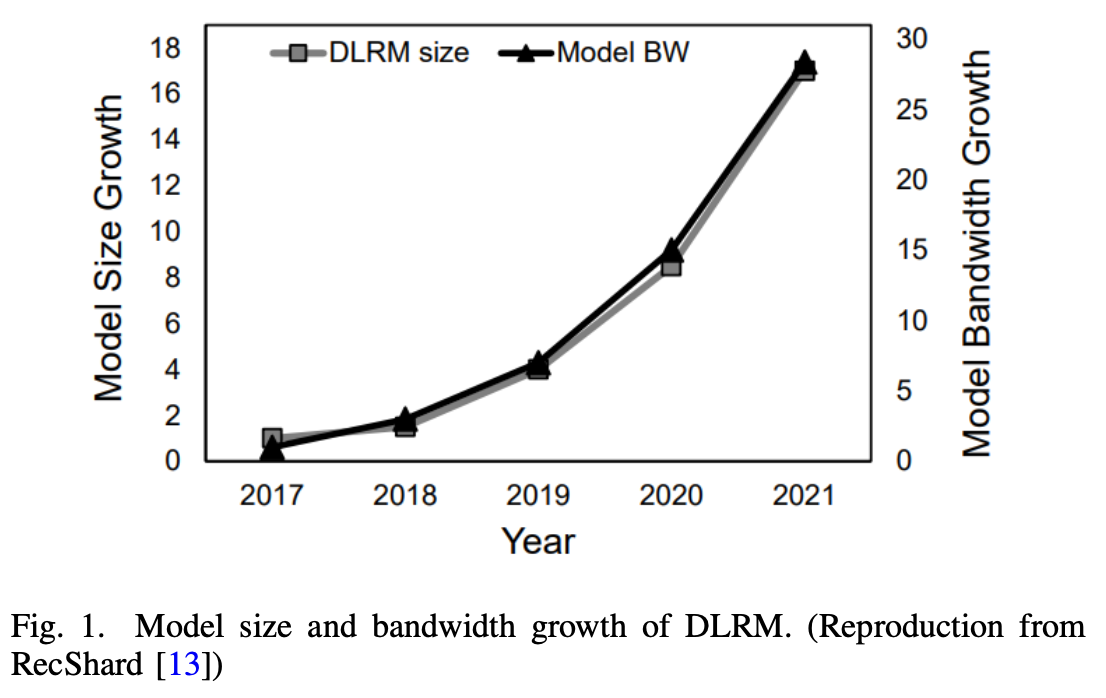
- This stems mainly from the operation’s tendency to exhibit sparse and irregular memory access patterns. As a result, these memory bound operations place significant constraints on traditional data center infrastructures [5], and this challenge continues to grow with the scale, as depicted in Figure 1.
- To tackle this challenge, recent efforts have concentrated on designing memory systems tailored to embedding operation. Approaches like TensorDIMM [6] and RecNMP [7] have explored the effectiveness of incorporating near-memory- processing (NMP) to alleviate the memory-bound nature by accelerating embedding operations directly within off-chip memory. These architectural solutions expedite the gather-and-reduce (GNR) process of embedding operations by deploying processing units in each rank of Dual Inline Memory Module (DIMM). This approach effectively harnesses the internal memory bandwidth, further amplified by the number of ranks in the memory channel. TRiM [8] and SPACE [9] followed a similar NMP structure while introducing other modifications to memory architecture. TRiM employed bank group-level processing-in-memory (PIM) within the DRAM device, while SPACE utilized High Bandwidth Memory (HBM) [12] as a Dynamic Random Access Memory (DRAM) cache.
- On the other hand, personalized recommendation models are currently expanding in its size. According to RecShard [13], the memory capacity requirement of the Deep Learning Recommendation Model (DLRM) has been enlarged 16 times from 2017 to 2021, as shown in Figure 1. The model’s growth is attributed to the fact that incorporating more items attributes to better model quality.
- However, the model operating on the inference server is significantly smaller in scale compared to the training model [13], [14]. Therefore, a significant gap exists between the training model size and the inference model size. Serving the inference with a multi-node server or introducing Solid-State-Drivers (SSDs) could be a possible solution. However, it comes at the cost of synchronization and vulnerability to failures for the multi-node server case, and the SSDs have a negative impact on execution time [15], [18]. Therefore, exploring an alternative approach is essential to optimize model inference without encountering these drawbacks.
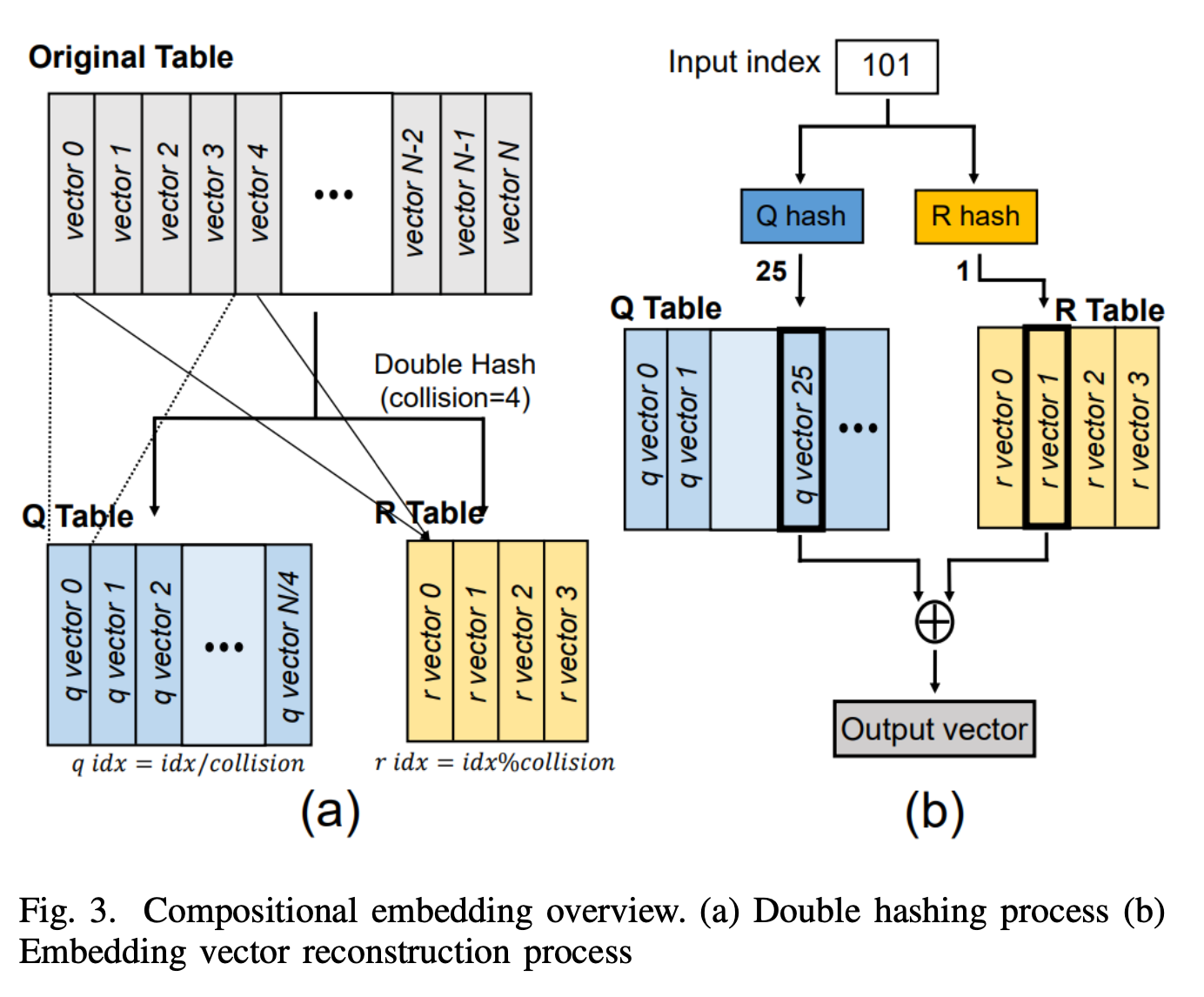
- Prior works took algorithmic approaches to reduce the embedding table size [19], [20], [21], [22]. While these techniques have successfully reduced the size of the embedding table, their work has been done at the cost of imposition of a much heavier burden on the memory bandwidth or inefficient memory capacity management. A representative method is compositional embedding [19], which employs a simple double-hashing technique to transform the original embedding table into a smaller quotient (Q) table and remainder (R) table. Nevertheless, this method necessitates double memory access, amplifying the memory- bound characteristics.
- We propose HEAM, a specialized memory architecture integrated with PIM technology, designed to accelerate the inference process of compositional embedding. HEAM introduces a three-tiered memory hierarchy consisting of DIMM, HBM, and a lookup table (LUT). HBM is incorporated with base-die PIM (bd-PIM), and bank-group PIM (bg-PIM), and LUT that serves as an additional storage space within bg-PIM.
- This design is based on the following observations. Similar to the original embedding, the Q table exhibits high temporal locality characteristics within a small portion of the entire embedding vector. Therefore, HEAM leverages HBM and DIMM to exploit this temporal locality, storing high temporal locality vectors to the HBM and others to the DIMM.
- Notably, the R table, in particular, has a very small size and demonstrates a remarkably high temporal locality. Hence, we utilize an LUT within bg-PIM to store the entire R table. By addressing the memory bandwidth challenges associated with compositional embedding, HEAM effectively reduces the size of the embedding tables while simultaneously satisfying the requirements for memory bandwidth. This capability enables the execution of large models on a single-node server at a high processing speed. The primary contributions of our work can be summarized as follows:
- To the best of our knowledge, HEAM is the first work to address both the large model size problem and the memory-bound issue of the DLRM. HEAM successfully tackles both issues by designing specialized hardware for compositional embedding.
- We propose an allocation strategy for each hash table in compositional embedding. By distinguishing storage space for each table based on the analysis of their unique characteristics, HEAM achieves additional gains in bandwidth.
- We design a two-level PIM within HBM, specifically tailored for compositional embedding. This enables HEAM to expand into a three-tiered memory system, incorporating DIMM, HBM, and the LUT within PIM, thus effectively enhancing memory parallelism. Using LUT facilitates the additional speedup of Processing-In-Memory (PIM) architectures.
Recommendation System Overview
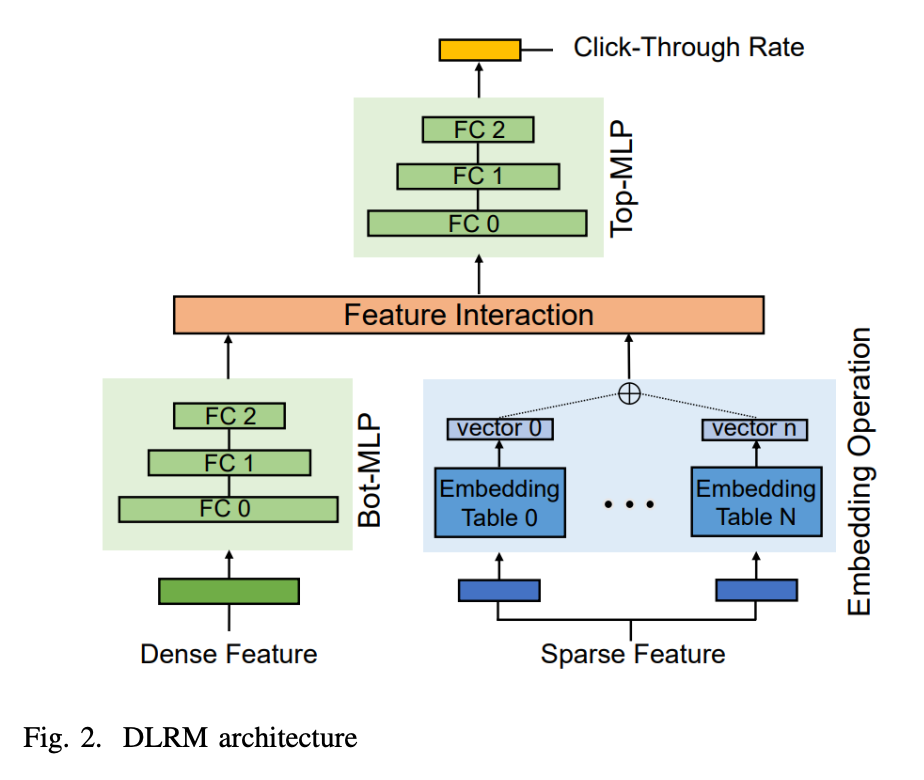
- Among the various personalized recommendation models employed by diverse companies, DLRM stands out as one of the prominent recommendation system models. In the DLRM framework, inputs are categorized into two groups: dense features and sparse features.
- Dense features correspond to user information expressed as floating-point values, while sparse features facilitate access to items by transforming them into embedding vectors that encapsulate item-specific features.
- The bottom-mlp takes dense features as inputs, while the embedding lookup process handles sparse features. The embedding lookup operation gathers individual embedding vectors from multiple embedding tables, generating a single reduced vector. This reduced embedding vector is subsequently concatenated with the outcome of the bottom-mlp through a feature interaction layer. The resulting combined representation is then fed into the top-mlp. Once the top-mlp completes its calculations, the final outcome, CTR, is generated.
Challenges in Recommendation System Inference
- The performance of the recommendation system is constrained by the memory-bound nature of the embedding operation. The irregular access patterns of embedding vectors, combined with the extensive size of the embedding table that surpasses the cache storage capacity on the host side, necessitate the frequent look-up of embedding vectors from the off-chip memory system. This frequent access to main memory leads to higher latency for the embedding operation than that of the bottom-mlp [9], classifying the model as memory-bound.
- Recently, recommendation models have been trending towards incorporating increasingly large-sized embedding tables, with their scale growing year by year [13]. Nowadays, industry- scale DLRM implementations require substantial memory resources, often reaching sizes of up to tens of terabytes, a significant portion of which is dedicated to housing embedding tables. Given that the quality of the model is closely linked to the size of these embedding tables, there is a strong incentive to utilize as large embedding tables as possible in production. However, the practical utilization of such large models is constrained by physical limitations, as the memory size of a single-node server is restricted by the available slots within the server.
NMP & PIM Designs for Recommendation System
- Recent studies have introduced NMP units within the DRAM architecture to meet the memory bandwidth requirements of recommendation systems. Specifically, these approaches have incorporated multiple DIMMs with NMP units situated within their DIMM/Rank configurations, effectively exploiting DIMM/Rank-level parallelism to achieve increased throughput.
- TRiM focused on the tree topological structure of the DRAM’s data path, further enhancing parallelism by integrating PIM units within each bank group. In these previous designs, NMP/PIM operations are not executed in a synchronized style as embedding vectors are accessed randomly. However, as each vector read requires more than one DRAM read access cycle (tRAS), a new NMP/PIM operation could be successfully transferred and initiated before the previous instruction in another NMP/PIM unit completes, resulting in parallel executions.
- In pursuit of additional speedup, the aforementioned designs have leveraged the long-tail distribution of embedding vectors, where a small subset of embedding vectors is frequently reused. This has been accomplished by incorporating a cache within the buffer chip [7] or implementing load-balancing techniques with the assistance of the memory controller [8]. While it is possible to increase the throughput of the embedding operation by incorporating more DIMMs with NMP designs from previous approaches, this may lead to inefficiencies in power consumption [9].
- To address this challenge, SPACE [9] introduced a heterogeneous memory system that combines HBM and DIMMs, with HBM functioning as a DRAM cache. Additionally, SPACE exploited the reduction locality of embedding vectors and the long-tail distribution of embedding vectors to achieve significantly higher throughput. In summary, achieving high performance in recommendation systems relies on core techniques that involve exploiting parallelism within the main memory and capitalizing on the long-tail distribution of embedding vectors.
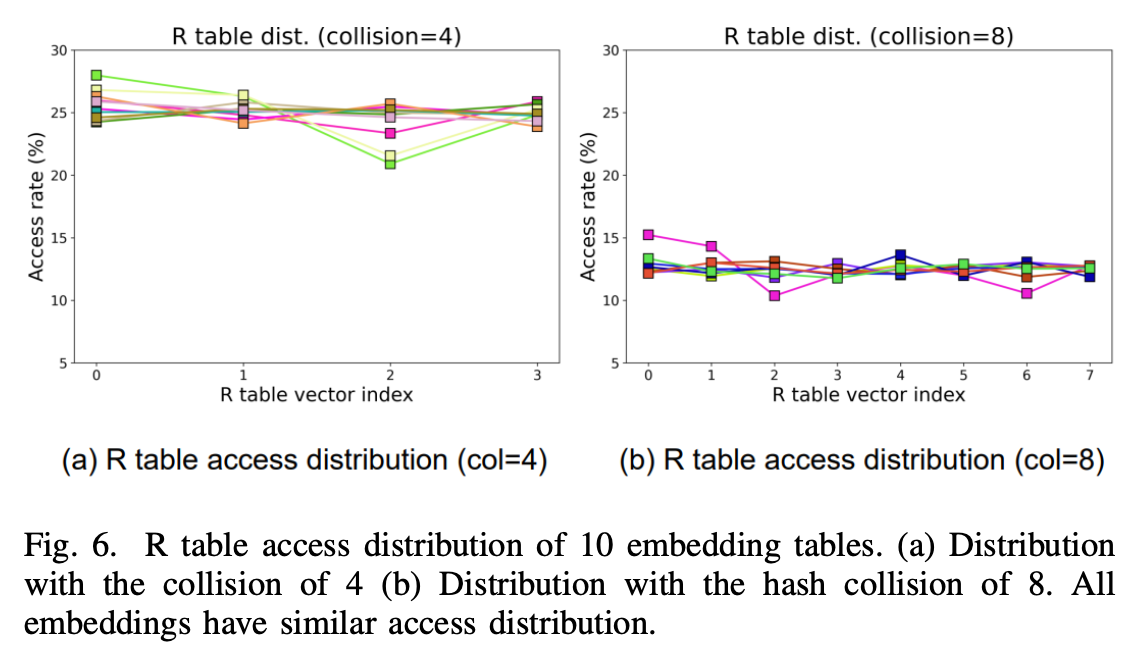
Opportunities for PIM Support
- The above assessments suggest that enhanced throughput support is necessary for running compositional embedding during the inference stage. Inspired by the previous works that utilize NMP/PIM to extend the bandwidth, we conclude that employing PIM is an effective solution for addressing the memory-bound characteristic of compositional embedding.
- Two attributes of compositional embedding make the usage of PIM more effective. First, as described in Section II-B, the data arrangement is suitable enough to employ the PIM architecture. This is due to the uniformity in vector dimensions, which ensures efficient use of memory capacity and consistency in the total DRAM burst needed for each vector. Second, unique features of the R table vectors, high temporal locality, and its uniform memory access distribution could be efficiently exploited by extending the PIM design to increase the throughput further. Integrated with a heterogeneous system consisting of HBM and DIMM with base die PIM, the utilization of PIM is an effective design for supporting compositional embedding.
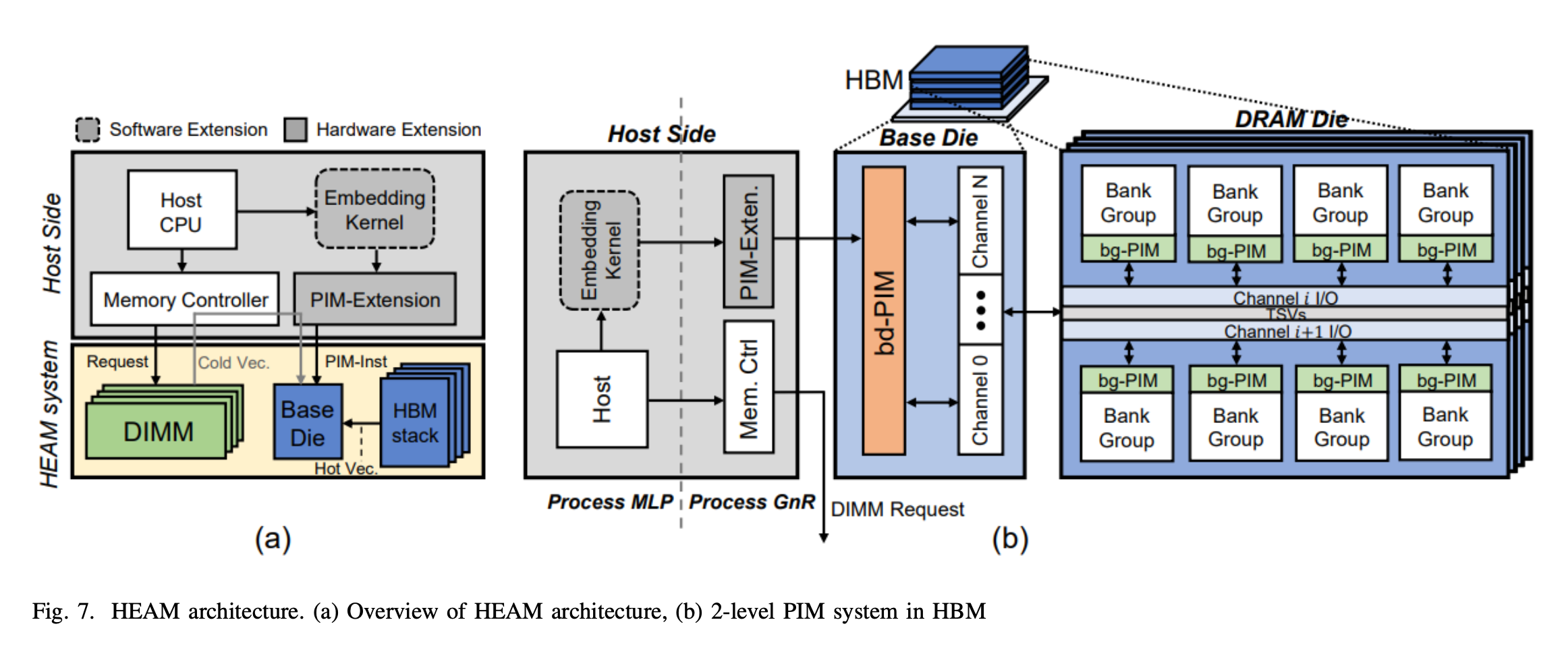
HEAM Architecture Overview
- We propose HEAM, a specialized memory system designed to enhance the bandwidth of DLRM when compositional embedding is employed. For the reconstruction operation of compositional embedding, addition is utilized in our system. The overall architecture is depicted in Figure 7. As illustrated in Figure 7 (a), the HEAM system incorporates a heterogeneous memory architecture that comprises HBM and DIMM, which addresses the memory-bound nature to some extent by offloading frequently accessed vectors to HBM. Nonetheless, it’s important to note that the overall memory access demands double when employing compositional embedding. As a result, depending on conventional HBM remains insufficient to achieve the required throughput.
- To tackle this problem, we design a two-level PIM system within the HBM to enhace the throughput by utilizing in- memory parallelism, thereby providing additional bandwidth support for the embedding operation. In Figure 7 (b), the first-level processing unit is located on the base die of the HBM, whereas the second-level processing units are located inside each bank group. These processing units are referred to as bd-PIM and bg-PIM, named based on their respective locations.
- Within these PIMs, the embedding operation is processed in a two-stage partial addition fashion. Initially, each bg-PIM collects Q embeddings and R embeddings from its dedicated bank group. Local addition is performed inside each bg-PIM on the collected embedding vectors, generating partial results. Note that Q embeddings and their corresponding R embeddings don’t have to be located in the same bank group, as addition operation is employed, resulting associative law property to be held in the operation. Once all bg-PIMs complete their respective operations, all the reduced vectors are forwarded to the bd-PIM. The same operation is carried out within the bd-PIM for each set of partial results, resulting in the final output delivered to the host processor.
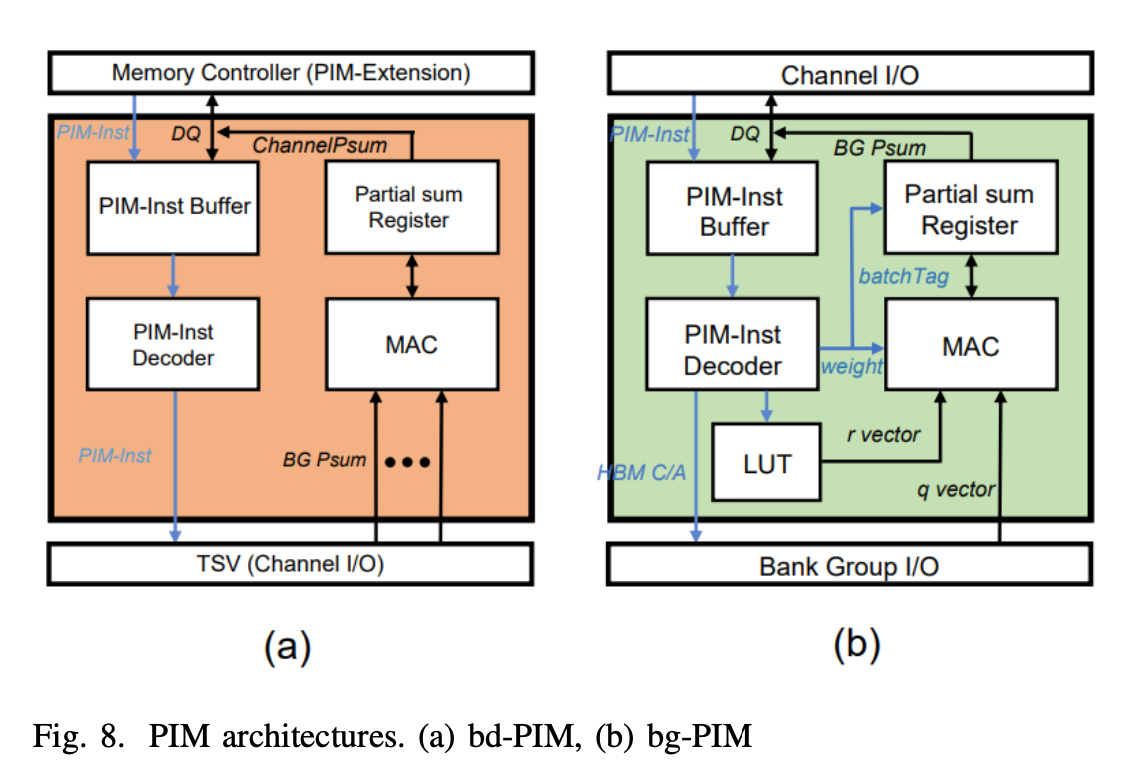
- Figure 8 (b) depicts the PIM architecture of bg-PIM. The system inside bg-PIM is equipped with an instruction register, an instruction decoder and a multiply-and-accumulate (MAC) unit. Additionally, LUT is integrated inside each bg-PIM to leverage the temporal locality of the R table described in Section III-B. Therefore, the access to R embedding vectors is always directed to the LUT, decreasing the total bank access. HEAM employs batching of 4 embedding operations to address the load imbalance issue, following the technique utilized in RecNMP [7].
- Batching compensates load imbalance issue of the embedding lookup, and the level of compensation increases with large vector size as operation overlap cycles between bank group also increases. To avoid introducing too much area overhead into bank groups, we use up to 4 batch in our system. The bd-PIM receives partial sums delivered from bg-PIM and processes the final GnR operation as illustrated in Figure 8 (a). Note that the architecture of the bd-PIM is similar to that of the previous works.
Conclusion
- We introduce HEAM, a three-tiered memory architecture that comprises DIMM, HBM featuring bd-PIM and bg-PIM and LUT inside bg-PIM. Our system tackles two key challenges in deep learning recommendation system: Model size expan- sion and Memory-bound operations. We examined the unique characteristics of compositional embedding and leveraged our findings to boost overall throughput.
- HEAM effectively resolves the issue of double memory access that arises when applying compositional embedding, resulting in 6.2× performance improvement and 58.9% energy savings compared to the previous NMP architectures tailored for recommendation systems.
'ComputerScience > OperatingSystem' 카테고리의 다른 글
| [PIM] Processing-in-memory: A workload-driven perspective (0) | 2024.05.21 |
|---|---|
| [PIM] Benchmarking a New Paradigm: An Experimental Analysis of a Real Processing-in-Memory Architecture (0) | 2024.05.17 |
| [Paper review] Xen and the Art of Virtualization (0) | 2024.03.15 |
| 1. Virtualization (0) | 2023.09.08 |
| [운영체제] 기말고사 Summary (0) | 2023.07.21 |